TCP-clouds, UDP-clouds, “design for fail” and AWS
An entire Amazon AWS Region was recently down for four days. Everyone has got to blog something about it and this is my attempt. Just as a warning: this post may be highly controversial.
There has been a litany of tweets pontificating how applications on AWS should be deployed in a certain way to achieve the maximum level of availability and how applications need to be "re-architected" to properly fit into the new cloud paradigm. Basically the idea is that your application should be thought, designed, architected, developed and deployed with failure in mind. Many call it "design for fail". That is to say: software architects and developers should never assume that any given piece of the infrastructure is reliable.
I beg to differ. I don't like this idea even though some of you will be thinking I am a bit archaic.
George Reese wrote a great blog post titled The AWS Outage: The Cloud's Shining Moment outlining the differences between the "design for fail" model and the "traditional" model. The traditional model, among other things, has high-availability and DR characteristics built right into the infrastructure and these features are typically application-agnostic (a couple of years ago I wrote a big document on the various alternatives for HA and DR of virtual infrastructures if you are interested). George nailed down the story very well and the story is that there are a couple of different philosophies at play here. I don't call these two models "design for fail" and "traditional" though. I call them TCP-clouds and UDP-clouds. Let's look at a summary of the characteristics of these two protocols.
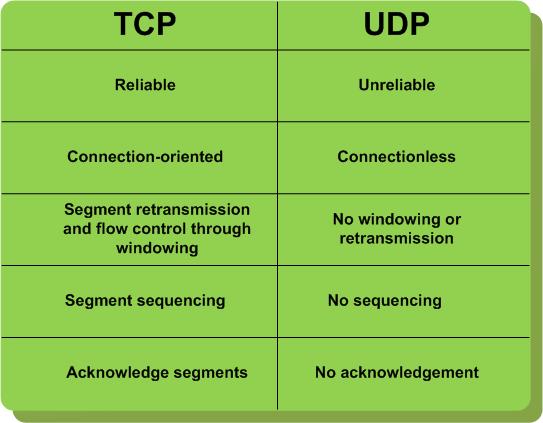
In the context of cloud resiliency this is what that means:
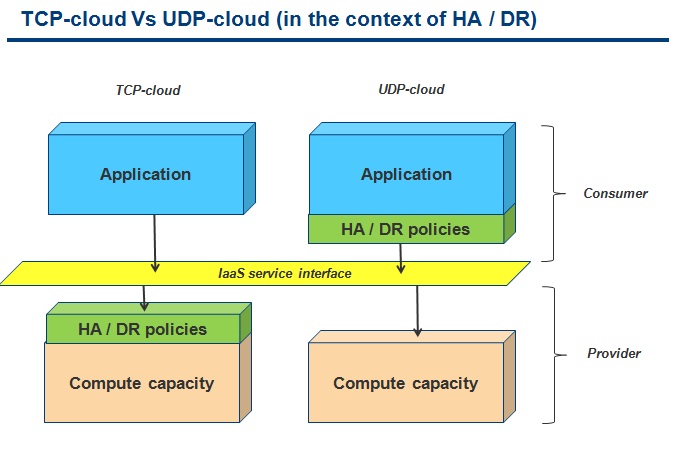
AWS uses a UDP-cloud model because it doesn't guarantee reliability at the infrastructure level. AWS essentially offers an efficient distributed computing platform that doesn't have any built-in high availability services. The notion of Availability Zones and Regions is often misunderstood since the name may imply there is high availability built into the EC2 service. That's not the case: AWS suggests to deploy in multiple Availability Zones simply to avoid concurrent failures. It's mere statistic. In other words, if you deploy your application in a given Availability Zone, there is nothing that will "fail it over" to another Availability Zone as part of the AWS service (RDS is a vertical example that does that for MySQL but I am instead talking about an application-agnostic service that does that for every application regardless of the nature).
Since I am not able at the moment to write a structured thought around this complex matter, let me write down mixed and random thoughts, opinions and questions to try to make you think. I am giving you some food for thoughts. As far as answers, call me when you find them please.
Isn't this "design for fail" theory a step back?
What we have seen in the last decade was a trend where we were able to remove the non-functional requirements complexity from within the traditional OS and put them down into the "virtual infrastructure" (arguably the backbone of any IaaS cloud). This is the point I was trying to come across during this VMworld 2007 breakout session 4 years ago. And what we are saying now is that we should put that logic back into the application (not even the Guest OS)? I thought the trend I have just described was quite successful and one of the many reasons of the success of virtualization deployments. Are we now questioning it? My idea is fairly simple although I am open to be challenged: developers focus on functional requirements, IT focuses on non-functional requirements (which includes resiliency and reliability among other aspects). If interested, you can download the full deck here. Note I did that presentation before joining VMware so, if you think I am biased, well I am biased just because I bought into that school of thought long before I was on the VMware's payroll system.
Excuse me? What did you say? NoSQL... to whom?
In his post George suggested exploring NoSQL solutions. Not a bad idea however, other than the risk of losing transactions that he was mentioning, I'd say 95% of the customers I have been working with so far would look at me strangely and they'd ask: "what do you e x a c t l y mean by NoSQL? Is it a bad word?". Let's be honest folks: this is not mainstream. If we want to create a cloud for an elite of people I am fine with that. However I am convinced one of the key values of an IaaS infrastructure is, among others, providing a cloud-like experience (pay-as-you-go, elasticity, etc) to traditional workloads. I am not philosophically against the idea of re-architecting applications, however I am also convinced that, for one person thinking about writing a brand new Ruby application for a UDP-cloud leveraging NoSQL (pardon me?)... there are at least 1.000 poor sysadmins trying to figure out how to live with their traditional applications.
Can you afford a personal Chaos Monkey?
Some of the AWS customers developed tools to test the resiliency of their applications. Do you remember the old good HA and DR plans? IT people would walk into the server room to power-off servers and eventually the entire datacenter to simulate a failure and see if their HA and DR policies were working properly. If everything was good applications could survive the failure (more or less) transparently. This is what a Chaos Monkey tool does, but with a different perspective: these are software programs that are designed to break things randomly (on purpose) in order to see if the application itself is robust enough to survive those artificially created infrastructure issues in the cloud. In a TCP-cloud it would be the cloud provider to run traditional tests to make sure the infrastructure could self-recover. In a UDP-cloud it is the developer to run these Chaos Monkey tests to make sure the application could self-recover since it's been "designed for fail". Now, my take is that if you are Netflix or the like of Nasa and JPMorgan (these two are just examples of big organizations - not even sure if they are on Amazon) then you may have enough motivation and business reasons to re-architect your application for a UDP-Cloud and create your own Chaos Monkey to test your "design for fail" deployment. Certainly at Netflix they know what they are doing and in fact they seem to not have been impacted by this AWS outage. But if you are these guys do you think you have bandwidth, knowledge and time to re-architect the application and test it for failure? That AWS forum discussion showed up during the 4 days debacle and it deserves a proper copy and paste just in case it gets lost:
< Sorry, I could not get through in any other way. We are a monitoring company and are monitoring hundreds of cardiac patients at home. We were unable to see their ECG signals since 21st of April.
> Man mission critical systems should never be ran in the cloud. Just because AWS is HIPPA certified doesn't mean it won't go down for 48+ hours in a row.
< Well, it is supposed to be reliable...Anyway, I am begging anyone from Amazon team to contact us directly.
This is shocking isn't it? Try to argue with them about NoSQL and "design for fail". They barely probably understand the notion of Availability Zones and Regions. Don't get me wrong. It's not these people's fault. They are not in the business to re-architect an application to be written with reliability in mind, they are in the business of helping their patients. Sure you can argue with them that it was their fault if they failed. But the net of this story is that they are not going to re-architect anything nor write a Chaos Monkey. When they realize what happened, they will look for a TCP-Cloud.
Design for fail: philosophy or necessity?
I hope you've got at least to this point because this is my biggest struggle at the moment. The more I read about suggestions to design applications for fail the more I miss whether these suggestions are tactical or strategic. In other words, are you suggesting to design for fail simply because that's the way Amazon AWS works today (but you'd rather use an Amazon TCP-cloud if that was available)? Or are you suggesting that, in any case, you should design an application for fail because you are happy to deal with a UDP-cloud and that's how every cloud should behave? Are we saying that it's strategically and philosophically better to have developers deal with application high availability and disaster tolerance because that's what makes sense to do? Or are we saying we need to do this because that's the only option we have on Amazon AWS (today) and there is no other choice? I know it may sound like a rhetoric question but it's actually not. Perhaps we need both models?
You don't like the noise coming from the other apartments? Buy the entire building!
This isn't related to the outage and the resiliency of the cloud but it relates to the overall TCP-cloud Vs UDP-cloud discussion. Similar to the "design for fail" there is the "deploy for performance" thread going on. In a multi-tenant environment (a must-have to achieve economy of scale and elasticity) there is obviously contention of resources. In an ideal world I'd like to be able to buy virtual capacity for what I need and have a certain level of guarantee that that capacity (or at least a contracted part of it) is always available for me. There are of course circumstances where I can trade-off performance and availability of capacity for a lower cost, but there are other situations where I cannot trade that off. A TCP-cloud should (ideally) be able to deliver that guarantee. A UDP-cloud works in best-effort mode and typically leverages statistical law to fight contention. This is the statistical assumption: not all users running on a shared infrastructure will be pushing like hell at the same time (one would hope - finger crossed).
So what do you have to do if you are running on a UDP-cloud? You keep the other people out of your garden.
I think Adrian is a genius but I don't agree with his point of view :
"...you cannot control who you are sharing with and some of the time you will be impacted by the other tenants, increasing variance within each EC2 instance. You can minimize the variance by running on the biggest instance type, e.g. m1.xlarge, or m2.4xlarge. In this case there isn't room for another big tenant, so you get as much as possible of the disk space and network bandwidth to yourself."
"...busy client can slow down other clients that share the same EBS service resources. EBS volumes are between 1GB and 1TB in size. If you allocate a 1TB volume, you reduce the amount of multi-tenant sharing that is going on for the resources you use, and you get more consistent performance. Netflix uses this technique, our high traffic EBS volumes are mostly 1TB, although we don't need that much space."
"If you ever see public benchmarks of AWS that only use m1.small, they are useless, it shows that the people running the benchmark either didn't know what they were doing or are deliberately trying to make some other system look better."
The last sentence is like saying that, if you buy a new apartment and then complain about the big noise coming from other apartments, it's your fault: you should have bought the entire building and enjoyed the silence! Hell Adrian, I say no! There must be a better way.
I think there must be rules in place to keep the noise at an acceptable level and if there is someone trying to scream all the time someone should "enforce" silence without having you to buy an entire building to cook and sleep in peace. That's how it works in real life, that's how it should work in the cloud. In my opinion at least.
In cloud terms I'd be ok if what I was buying always delivers a contracted baseline as a guarantee and then can burst (I said burst Beaker, not cloudburst) to higher throughput if there isn't contention. What I would NOT be ok with is no baseline at all so what I get is no predictable performance all times. BTW note that Amazon made a step forward in the right direction a few weeks ago announcing the availability of what they call dedicated instances. This is an attempt to solve the noisy neighbors problem. However in doing so they did trade off multi-tenancy (hence the higher cost of such a service).
For the records I have to say that I don't think there is a single public cloud at the moment delivering such a fine grained QoS across all subsystems on rented resources. This is a generic discussion about TCP-clouds and UDP-clouds and if you interpreted it like a vCloud Vs AWS shootout you are mistaken. In fact I think George gave vCloud too much credit in his blog associating it to the "traditional" datacenter model. There is a gap between what we can deliver, in terms of non-functional requirements, with a raw vSphere deployments and what we can deliver with a vCloud Director 1.x implementation. I am not hiding this by any means, in fact you can read here (the post but more importantly the comments) what I had to say about this. Having this said I believe VMware has a vision to fill that gap and create a true TCP-cloud. Last but not least I don't see why a VMware service provider partner shouldn't be able to implement a vCloud-powered UDP-cloud if need be.
PaaS and Design for fail?
If I struggle with IaaS clouds (and I do), go figure with PaaS clouds. To me PaaS is all about moving the level of abstraction at a higher level. IaaS is all about hiding infrastructure details. PaaS is all about hiding infrastructure and middleware details. In a PaaS you can upload your WAR file and that's it. It's the PaaS cloud provider that is going to deal with the complexity of setting up, managing and maintaining the middleware stack that can interpret that WAR file (for example). Fundamentally the developer should focus (even more than with IaaS) on the functional requirements of the application and let the cloud provider deal with the non-functional requirements aspect of it. Last time I checked HA and DR were still part of the non-.functional requirements domain. Note that, ironically, it may be easier for a PaaS cloud provider to build out-of-the-box resiliency given the nature of the interfaces they are exposing. Amazon is half way through that already with their RDS "My-SQL as a service": they already offer automatic failover across Availability Zones and they would just need to extend this failover support across regions (this would have helped with the recent failure by the way). So, if my theory is sound, that means that if you are architecting your application for PaaS you shouldn't design for fail. Upload your WARs, create a db instance on the fly and you are done. The cloud provider will figure out how to failover to the next server, to the next datacenter room or to another geography should a problem occur at any of the given levels.
So why isn't Amazon offering resiliency and reliability as part of their cloud services in the end?
After all they offer other non-functional requirements such as automatic scaling of applications through tools such as Autoscaling. So why would Amazon offer auto-scale services and shouldn't offer an automatic, agnostic, infrastructure-level recovery service across Availability Zones (or even better across Regions)? Guess what. It is at least two order of magnitude easier to instantiate a new web server and add an IP to a load balancer than implementing a (reasonably performant) backend traditional database that can geographically fail over without losing transactions in case of a disaster. Dealing with stateless objects is a piece of cake. Try to deal with statefull objects if you can.
I am sure Amazon doesn't think that dealing with autoscaling is something the cloud should do for developers whereas dealing with reliability and DR is something a developer should do on his/her own. What do you think? My speculation is that they are simply not there yet. As easy as it sounds. But don't be fooled. Amazon is full of smart people and I think they are looking into this as we speak. While we are suggesting (to an elite of programmers) to design for fail, they are thinking how to auto-recovery their infrastructure from a failure (for the masses). I bet we will see more failure recovery across AZs and Regions type of services in one form or another from AWS. I believe they want to implement a TCP-cloud in the long run since the UDP-cloud is not going to serve the majority of the users out there. Mark my words. I'll have to link to this blog post once this happens and I'll have to say "I told you" (I hate this). And that is only going to be a good thing because developers will start again to focus on functionalities and IT the cloud will continue to focus on making sure those functionalities are (highly) available.
As I said, just food for thoughts. If you find definitive answers, please let me know.
Last but not least this is a good time to remind the disclosure of my blog (courtesy of a big copy and paste from the Sam Johnston's blog): "The views expressed on these pages are mine alone and not (necessarily) those of any current, future or former client or employer. As I reserve the right to review my position based on future evidence, they may not even reflect my own views by the time you read them. Protip: If in doubt, ask."
Massimo.