VMware Harbor as a Rancher catalog entry
In the last few months I have been looking at Rancher (an open source container management product) as a way to learn more about Docker containers and understand better the ecosystem around them.
One of the things that appealed me about Rancher is the notion of an extensible catalog of application and infrastructure services. There is an official catalog tier called Library (maintained and built by Rancher the company), there is a “community” catalog tier called Community (maintained by Rancher the company but built and supported by the Rancher community) and then there is a “private” tier (where you can add your own private catalog entries that you own and maintain).
While Rancher supports users to connect to cloud based registries, I noticed there is only one container registry package in the Community catalog that one can deploy and manage (that is Convoy Registry). I thought this was a great opportunity (and a great learning exercise) to add VMware Harbor (an Enterprise class container registry) as a private catalog item option.
If you know Rancher, something like this. If you will.

What you will see and read below should be considered, literally, the proof of a concept that, in its current shape and form, can’t be used as-is for production purposes. Having that said, if there is enough appetite for this, I am willing to work more on it and refine some of the rough edges that exist today.
Acknowledgements
Before we dive into the topic, I want to thank Raul Sanchez from Rancher that has (patiently) answered all of my questions (and fixed some of my broken yaml). Without his help this blog post would have been much shorter. Oh I also want to thank my wife and my dog (although I don’t have a dog), because everyone does that.
An escalation of difficulties learning opportunities
It became immediately very clear that there were different set of tasks I needed to accomplish to be able to achieve the initial goal. One task was, usually, dependent on the other.
In order to be able to create a Rancher catalog entry, you need to be able to instantiate your application from an application definition file (when using the default Cattle scheduler that would be a standard Docker Compose file) as well as a Rancher Compose file. You can’t really run any shell script or stuff like that as part of a Rancher catalog entry.
If you explore how Harbor gets installed on a Docker host (via the documented “on-line installer"), it’s not really compatible with the Rancher catalog model.
With the standard on-line installer, you have to download the Harbor on-line tar.gz installer file, you have to explode it, you have to set your configuration settings in the harbor.cfg file, you have to run a “prepare” script that takes the harbor.cfg file as an input and create configuration files and ENVIRONMENT variables files for you to THEN, eventually, run the Docker Compose file passing the config files and ENVIRONMENT variable files as volumes and directives of Docker Compose (note some of these steps are buried under the main install script but that's what happens behind the scenes). At this point the Docker Compose file actually grabs the docker images off of Docker Hub and instantiate Harbor based on the configuration inputs.
At the end, what started as a simple “PoC project", turned into three "sub-projects”:
- Dockerizing (is this a word?) the Harbor on-line installer so that you can include the “preparation” procedure as part of the Docker Compose and pass input parameters as variables to Docker Compose (instead of editing the harbor.cfg file manually and perform the whole preparation circus)
- Rancherizing (this is not definitely a word!) the dockerized Harbor on-line installer and create a Rancher private catalog entry that mimic the typical single-host Harbor setup
- As a bonus: rancherizing the dockerized Harbor on-line installer and create a Rancher private catalog entry that allows Harbor to be installed on a distributed cluster of Docker hosts
Note that, while I had to create a dockerized Harbor on-line installer to fit the Rancher catalog model, you can also use it for other use cases where you need to automatically stand up Harbor but you don’t have a way to do that manually and interactively (Rancher being one of those use cases).
In the next few sections, I am going to cover in more specific details what I have done to implement these sub-projects.
Sub-project #1: Dockerizing the Harbor on-line installer
At the time of this writing, Harbor 0.5.0 can be installed either using an OVA or through an installer. The installer can be on-line (images get dynamically pulled from Docker Hub) or off-line (images are shipped as part of the installer and loaded locally).
We are going to focus on the on-line installer.
As we have alluded already, once you download the on-line installer, you have to “prepare” your Harbor installation by tweaking the parameters of the harbor.cfg file that ships with a template inside the install package.
The resulting set of configurations are then passed as an inputs to the Docker Compose file (via local directories mapped as “volumes” and via the “env_file” directive).
Wouldn’t it be easier/better if you could pass the Harbor setup parameters directly to the Docker Compose file without having to go through the “preparation” process?
Enter harbor-setupwrapper.
Harbor-setupwrapper is a Harbor installer package that includes a new docker image which (more or less) implements, in a docker container, the preparation process. This container accepts, as inputs, Harbor configuration parameters as environment variables. Last but not least the container runs a script that launches the preparation routines (this is all self-contained inside the container).
The Dockerfile for this image and the script that kicks off the preparation routines that ships with it are worth a thousand words.
If you will, what the harbor-setupwrapper.sh does, is very similar to what the install.sh does for the standard Harbor on-line installer.
We now have a new Docker Compose file which is largely based on the original Docker Compose file that ships with the official on-line installer. You can now “compose up” this new Docker Compose file passing the parameters that you would have otherwise tweaked in the harbor.cfg file.
This is a graphical representation of what I have done:
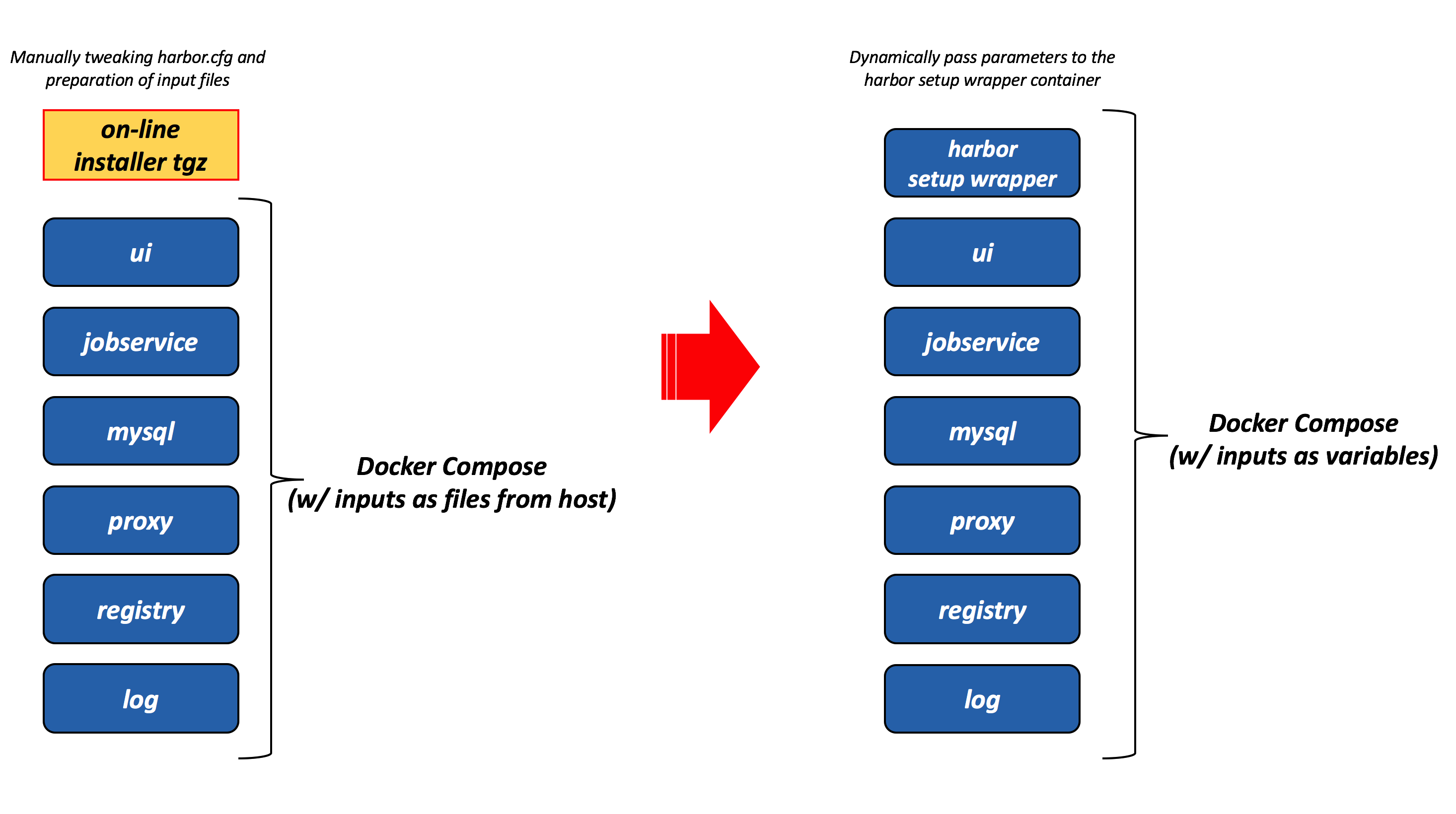
Remember this is just a PoC. Mind there are caveats!
- I have only really tested this with the HARBORHOSTNAME and HARBOR_ADMIN_PASSWORD variables. Other variables should work but I haven’t tested them
- There will definitely be scenarios where this will break. For example, I haven’t implemented a way to create certificates if you choose to use a secure connection (https). This would need to be implemented as additional logic inside *harbor-setupwrapper.sh *(hint: do not try to enable https because weird things may happen)
- The original on-line installer is (really) meant to be run on a single Docker host. The approach I have implemented in this new install mechanism honors that model and assumes the same constraints
- Because of the above, I didn’t even try to deploy this compose file on a distributed Swarm cluster. BTW, in the transition from “legacy Swarm” to “Swarm mode” Docker Compose doesn’t seem to have gained compatibility with the latter and given I didn’t want to waste too much time with the former, I have just opted to not test it in a Swarm environment
- More caveats that I haven’t thought about (but that certainly may exist!)
Making available the configuration files from the wrapper (generated by the harbor-setupwrapper.sh script) to the application containers was the easy piece. I have achieved that with the “volumes_from” directive where the application containers would grab their relevant configuration files directly from the wrapper container.
What proved to be more challenging was figuring out a way to pass the ENVIRONMENT variables (that are, again, in various files on the wrapper container) to the application containers. I could not use the “env_file” directive in compose because the value of the directive refers to files that are visible to the system where the compose is run from (whereas in my case those files were inside the wrapper container). Long story short, I ended up tweaking the ENTRYPOINT of the application containers to point to a script that would, first, load those environment variables and, then, it would start the original script or command that was in the original ENTRYPOINT. If you are curious, you can check all the entrypoint.sh* files on the harbor-setupwrapper GitHub repo.
If you want to play with this and setup Harbor using this new mechanism, all you need to do is cloning the harbor-setupwrapper repo and "up" the Docker Compose file you find in the harbor-setupwrapper directory. However, before you launch it, you will have to export the HARBORHOSTNAME and the HARBOR_ADMIN_PASSWORD variables. This is the equivalent of tweaking the harbor.cfg file in the original installer. If you forget to export these variables, Docker Compose will show this:
1root@harbor:~/harbor-setupwrapper# docker-compose up -d
2WARNING: The HARBORHOSTNAME variable is not set. Defaulting to a blank string.
3WARNING: The HARBOR_ADMIN_PASSWORD variable is not set. Defaulting to a blank string.
4Creating network "harborsetupwrapper_default" with the default driver
5...
At a minimum the HARBORHOSTNAME variable needs to be set and it needs to be set to the IP address or FQDN of the host you are installing it on (otherwise the setup will not be functional for reasons that I am going to explain later in the post). If you do no set the HARBOR_ADMIN_PASSWORD variable you will have to use the default Harbor password (Harbor12345).
What you want to do is this:
1root@harbor:~/harbor-setupwrapper# export HARBORHOSTNAME=192.168.1.173
2root@harbor:~/harbor-setupwrapper# export HARBOR_ADMIN_PASSWORD=MySecretPassword
3root@harbor:~/harbor-setupwrapper# docker-compose up -d
4Creating network "harborsetupwrapper_default" with the default driver
5Creating harbor-log
6...
Hint: if you keep bringing up and down Harbor instances on the same host and you intend to start them from scratch, please remember to get rid of the /data directory on the host (because that is where the state of the instance is saved, and new instances will inherit that state if the instances find that directory).
Sub-project #2: Creating the Rancher catalog entry for the single-host deployment
Now that we have a general purpose dockerized Harbor installer that we can bring up by just doing a “compose up”, we can turn our attention to the second sub-project. That is, creating the structure of the Rancher catalog entry.
I thought this was the easy part. After all, this was pretty much about re-using the new docker-compose.yml file we discussed above, in the context of Rancher. Right? Well...
I have learned (the hard way) that the devil is always in the details and, particularly in the context of containers, a tweak here to “fix” a particular problem often means opening up a can of worms somewhere else.
I will probably report hereafter more than what you would need/want to read to be able to consume this package but I am doing so to share my pains in the hope they may help you in other circumstances (I am also documenting my findings otherwise I will forget in 2-week time).
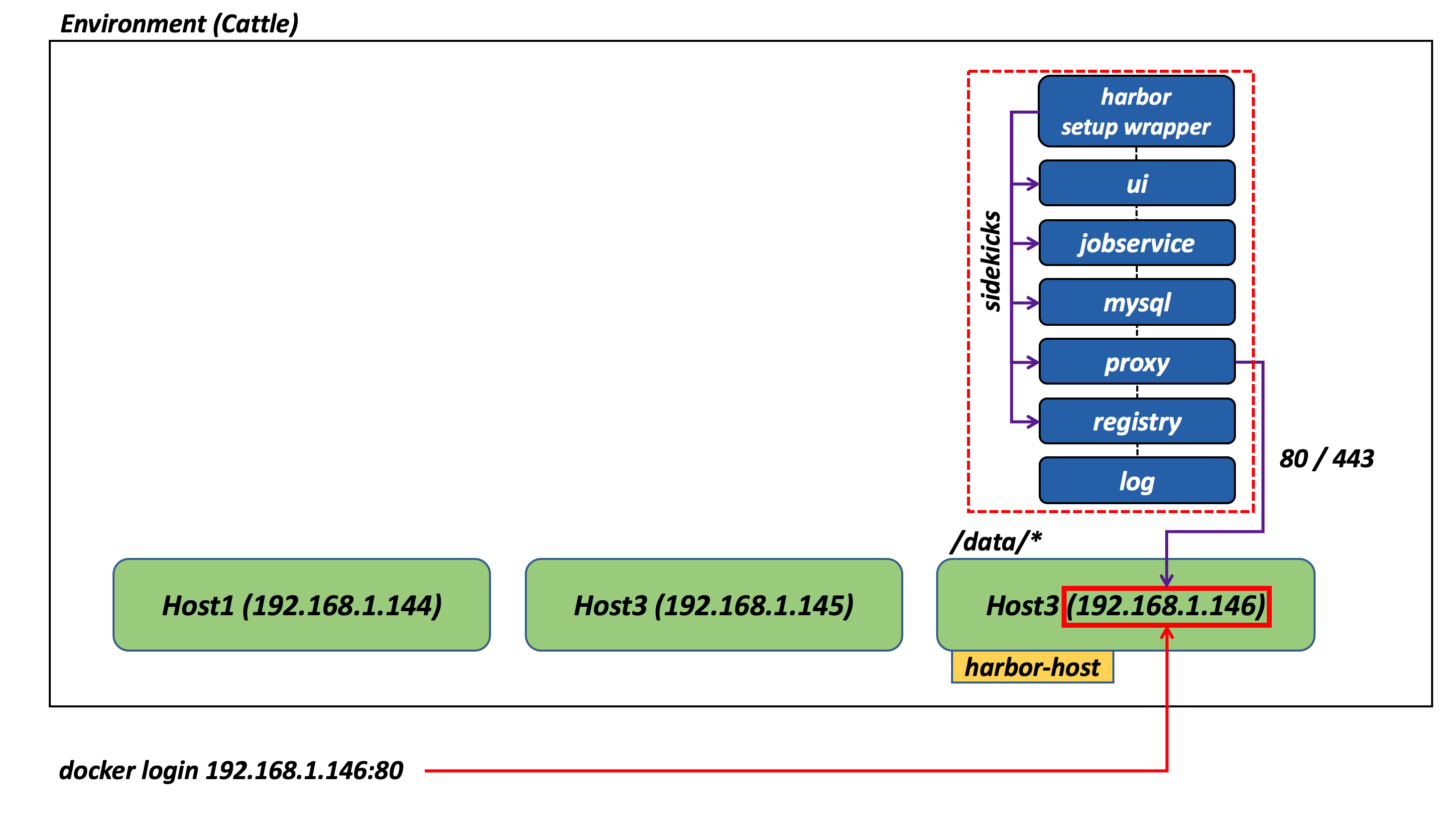
First and foremost, in Rancher, you can only do “volume_from” within the context of a sidekick. I have originally played with adding “io.rancher.sidekicks: harbor-setupwrapper” to every container in compose. However, I suddenly found out that this would create a harbor-setupwrapper helper container for every container that this was declared a sidekick of. Albeit this sounded ok to start with, I eventually figured that running multiple instances of the preparation scripts for a single Harbor deployment may lead to various configuration inconsistencies (e.g. tokens signed with untrusted keys, etc.).
I had to revert back to a strategy where I only had one instance of the harbor-setupwrapper container (that would generate consistently all the configuration files in one go) and I have accomplished that by making it the main container with all the other application containers being sidekicks of it. Practically, I just added “io.rancher.sidekicks: registry, ui, jobservice, mysql, proxy” as a label of the harbor-setupwrapper container. Warning: I did not tell Raul this and this may horrify him (or any other Rancher expert). But it works, so bear with me.
As usual, we fixed a problem by opening up another. Name resolution with sidekick containers doesn’t really work the way you expect it to work so I had to put in place another workaround (if you are interested you can read the problem and the fix here).
There were another couple of problems I had to resolve in the process of creating a Rancher catalog entry:
- Harbor requires that the variable “harborhostname” is set to the exact value that the user will use to connect to that harbor instance.
- All Harbor containers needs to be deployed on a single host which is more likely going to be one of the hosts of a (Cattle) cluster of many hosts.
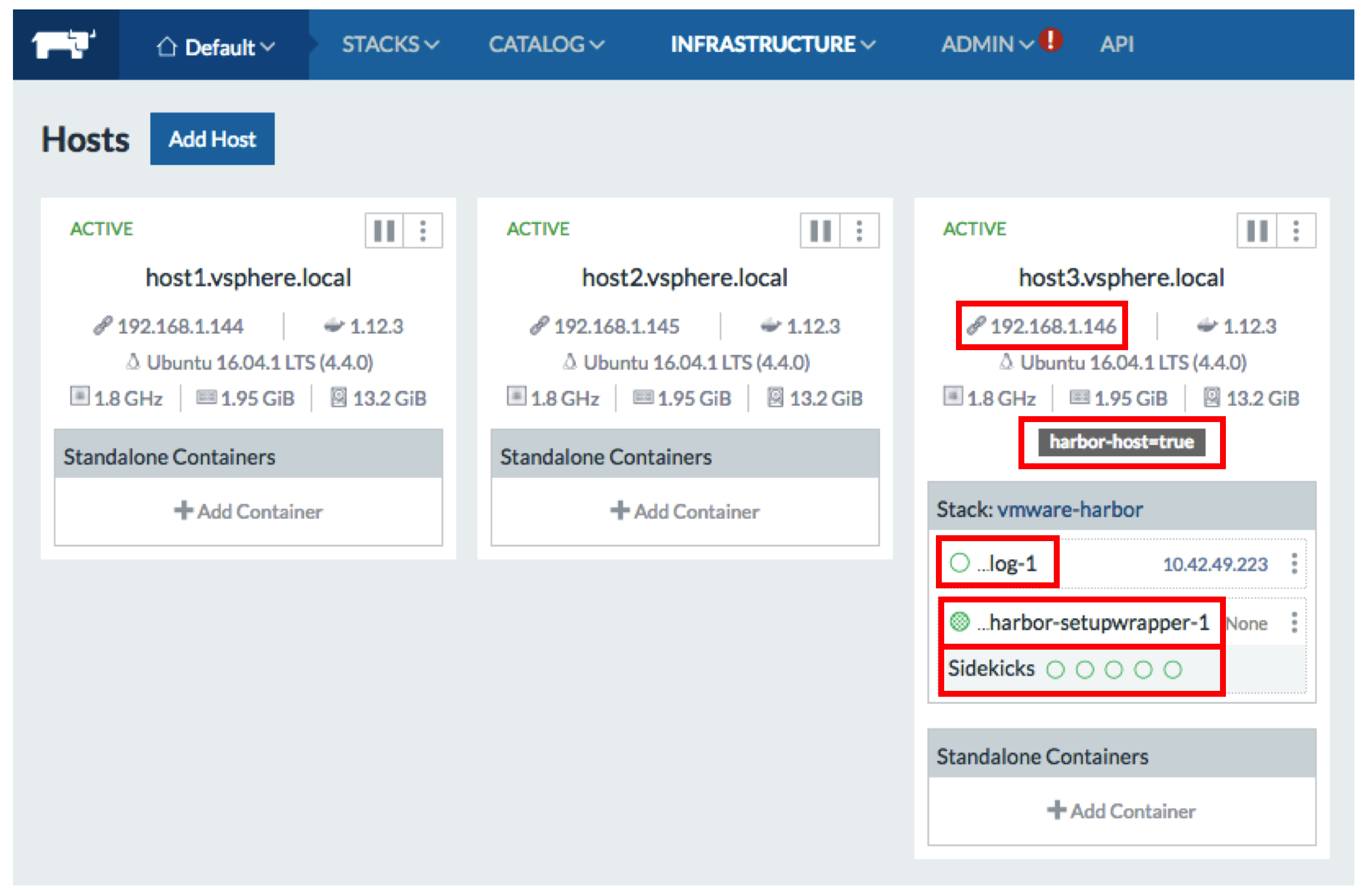
Again, in a move that may horrify Rancher experts, I have configured the Docker Compose file to schedule all containers on the host that has a “harbor-host=true” label.
This allowed me to make sure all containers get deployed on the same host (and, more importantly, have some degree of control over which one that is). In fact, given that I know which host my containers are going to land on, I can choose wisely the variable “harborhostname”. That could be the host IP address or the host FQDN.
Last but not least the Docker Compose file will publish ports 80 and 443 of the proxy container on the host (it goes without saying that those ports need to be free on that host, otherwise the deployment will fail). Again, perhaps not a great best practice but something basic and easy that works.
Note: remember that state is saved in the /data directory of the host so if you intend to bring up and down instances of Harbor for test purposes, you need to be aware that state is kept there across multiple deployments. This is far from how you’d run a true cloud native application but it is how Harbor (0.5.0) is architected and I am just honoring the original operational model in the Rancherization scenario for single host.
The following picture shows the details and relationships of the various components in a single-host deployment:
As a recap, at the high level, the current status of the Harbor private catalog entry for Rancher for single-host deployment is as follows:
- It only works with the Cattle scheduler
- Building Harbor catalog versions for Swarm and K8s based off the Cattle version should be relatively trivial (last famous words)
- This catalog entry inherits all of the limitations of the dockerized on-line installer described above (e.g. it doesn’t support https etc)
- The Docker hosts where you pull/push images need to have the “–insecure-registry” flag set on the Docker daemon (because we can only fire up Harbor with http access)
- One of the hosts will have to have the “harbor-host=true” label for the docker-compose to work and schedule containers properly
- The host with the “harbor-host=true” label will have to have ports 80 and 443 available
You can locate the deliverable for this sub-project inside my overall Rancher catalog extension repo.
You can watch the single-host deployment in action in this short video.
Sub-project #3: Creating the Rancher catalog entry for the distributed deployment
This is the part where I have learned the most about the challenges of operationalizing distributed applications. It was definitely a fun useful ride.
While Harbor is shipped as a containerized application, there are some aspects of it that do not make it an ideal candidate for applying cloud native application operational best practices. It doesn't really adhere to The Twelve-Factor App methodology.
First and foremost, the Harbor installer has been built with the assumption that all 6 containers are run on a “well-known” single host. Let me give you a couple of examples that may underline some of these challenges. We may have already mentioned some of those:
- The Harbor package comes with an embedded syslog server that the Docker daemon talks/logs to. If you look at the original Docker Compose file, you will notice that all application containers log to 127.0.0.1 implying and assuming that the syslog is running on the same host of all other containers
- You have to enter (as a setup parameter) the exact harbor hostname that users will use to connect to the registry server. Ideally, in a cloud native context, an app should be able to work with any given IP / FQDN that has been associated with it. As a last resort you should have an option to set (post-setup) the proper IP/FQDN endpoint that the app should be using. With Harbor 0.5.0 you have to know (upfront) what that IP/FQDN is before launching the setup (making things a bit more difficult to operationalize in a dynamic, self-service and distributed environment). That is to say: if your harbor service will happen to be exposed to users as “service123.mycompany.com” you have (had) to enter that string as the FQDN at deployment time (without even possibly knowing which hosts the containers are going to be deployed on)
- As part of the assumption that Harbor runs on a single well-known host, the product saves its own state on local directories on the host it is deployed onto. This is accomplished by means of various directory mappings in the containers configuration
The goal for this sub-project is to make Harbor run distributed on a Cattle cluster and no longer on a well-known host.
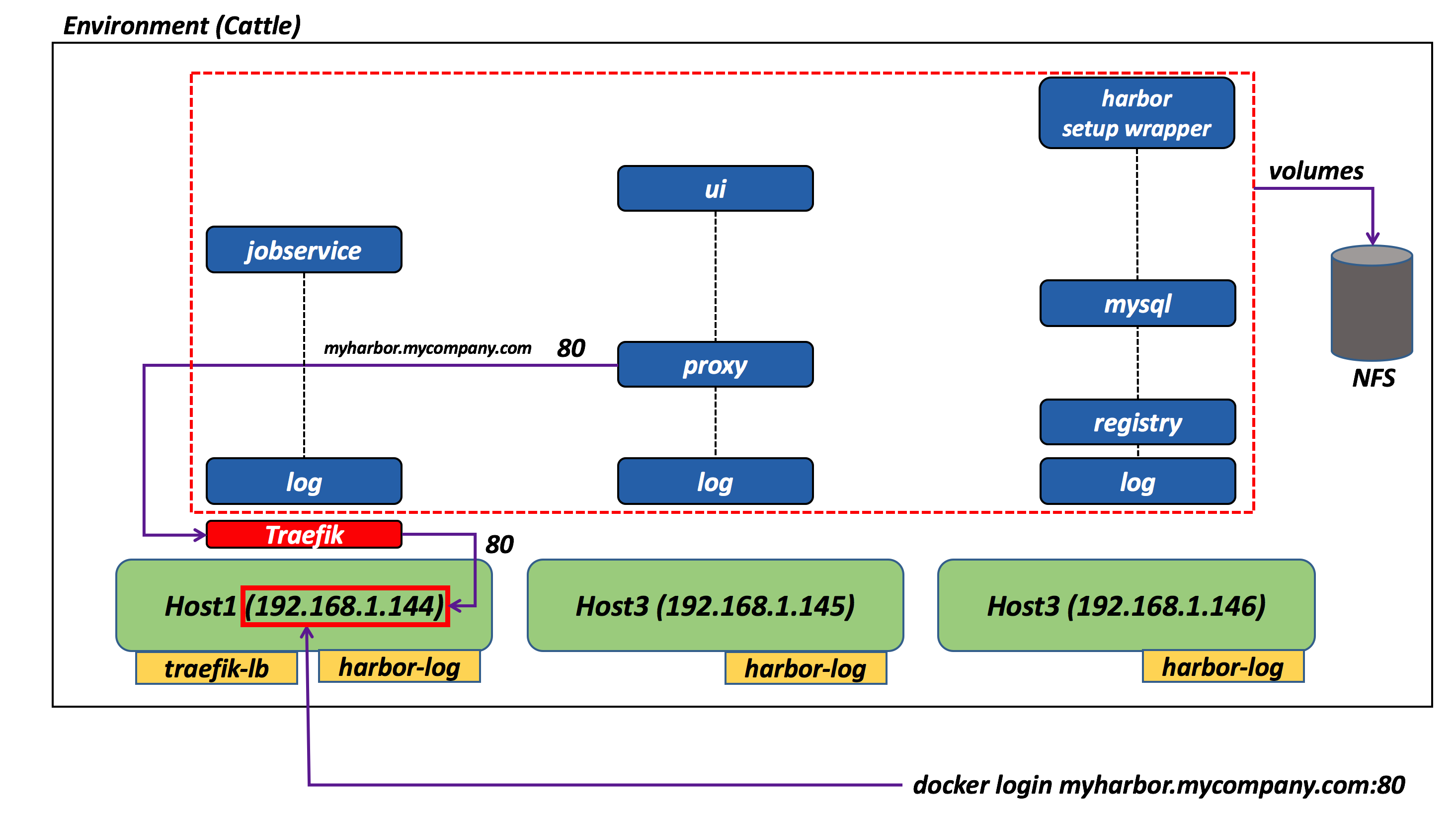
In order to do that the log image gets instantiated on every node of the cluster (requirement: each node has to have the label “harbor-log=true”). A more elegant solution would be to have a separate syslog server to point to (thus getting rid completely of the log service in Docker Compose).
Also, given we don’t know which host the proxy server is going to end up on (and given that in this scenario we wanted to implement a low touch experience in terms of service discovery) we have implemented the Harbor distributed model by leveraging Traefik (as explained in this blog post by Raul). If you are familiar with Docker, what Traefik does is (somewhat) similar to the “HTTP Routing Mesh” out-of-the-box experience that Docker provides with Swarm Mode. Please note that the proxy container ports (80 and 443) do not get exposed on the host and Traefik is the only way to expose the service to the outside world (in this particular distributed implementation).
The overall idea is that your DNS can resolve the IP of where Traefik runs and then Traefik “automagically” adds the hostname you have entered at Harbor setup time to its configuration. Check Raul's blog post for more information on the setup concepts.
Storage management has been another interesting exercise. In a distributed environment you can’t let containers store data on the server they happen to run on at any given point in time.
If the container is restarted on another host (due to a failure or due to an upgrade) it needs to get access to the same set of data. Not to mention if other containers (that may happen to run on different hosts) need to access the same set of data.
To overcome this problem, I opted to use the generic NFS service Rancher provides. This turned out to be useful, flexible and handy because it allows you to pre-provision all the volumes required (in which case they persist across re-instantiation of the Harbor catalog entry) or you can let Docker Compose create them automatically at instantiation time (in which case they will be removed when the Harbor instance gets brought down). Please note that, to horrify the purists, all volumes are mapped to all the application containers (except the log and proxy container which don't require volumes). There is vast room for optimization here (as not all volumes need to be mapped to all containers) but I figured I’ll leave it like that for now.
This approach leaves all the hosts stateless as there is no volume directories mapping in Docker Compose (all volumes are named volumes that live on the NFS share).
The following picture shows the details and relationships of the various components in a distributed deployment:
This picture shows the actual deployment in action in my lab:
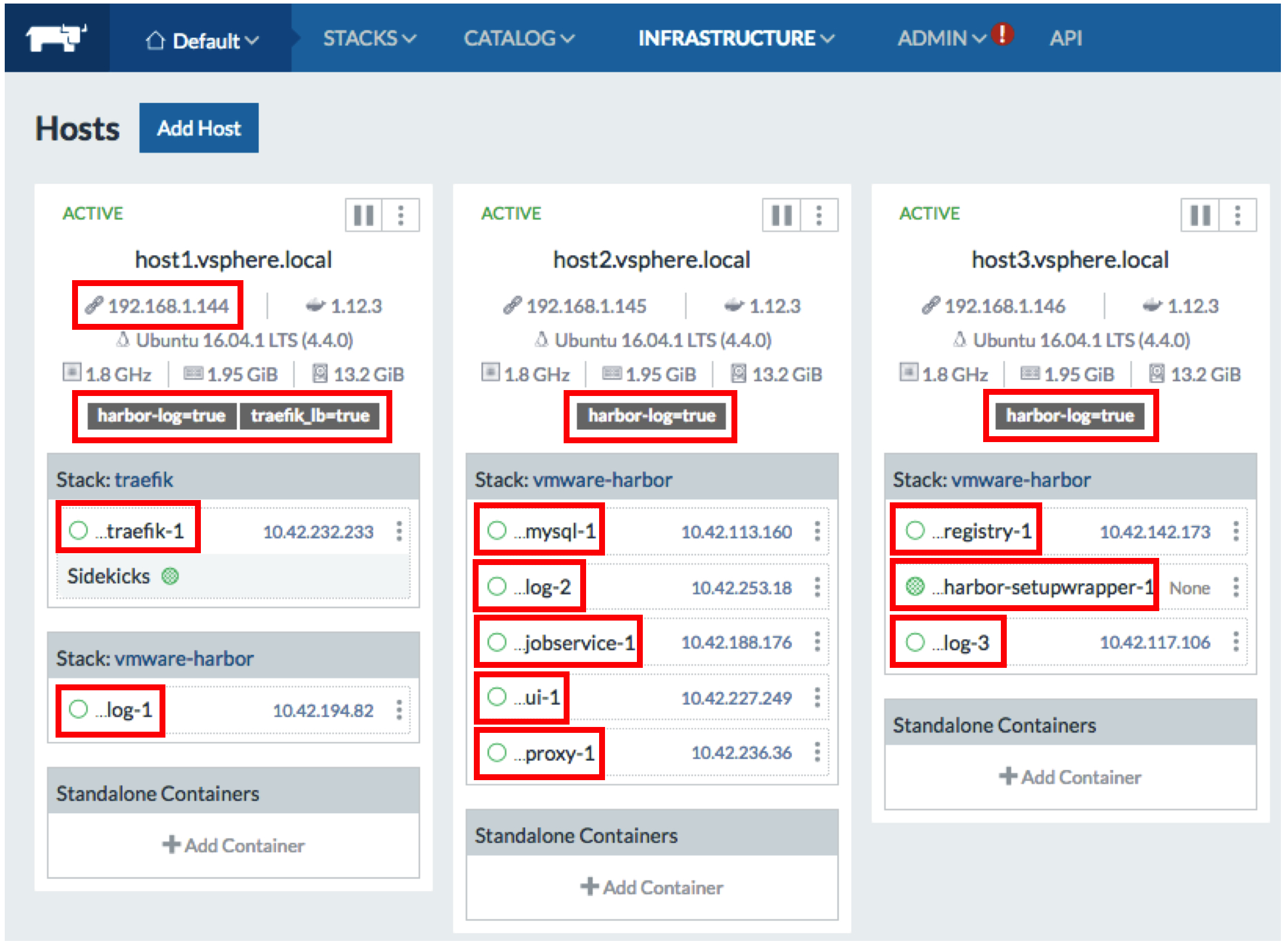
As a recap, at the high level, the current status of the Harbor private catalog entry for Rancher for distributed deployment is as follows:
- It only works with the Cattle scheduler
- Building Harbor catalog versions for Swarm and K8s based off the Cattle version should be relatively trivial (last famous words)
- This catalog entry inherits all of the limitations of the dockerized on-line installer described above (e.g. it doesn’t support https etc)
- The Docker hosts where you pull/push images need to have the “–insecure-registry” flag set on the Docker daemon (because we can only fire up Harbor with http access)
- All of the hosts in the cluster will have to have the “harbor-log=true” label for the docker-compose to work and schedule the log image properly
- The Traefik service (found in the Community catalog) needs to be up and running for being able to access Harbor from the outside. This has been tested exposing port 80 (note the Traefik default is 8080)
- The NFS service (found in the Library catalog) needs to be up and running and properly configured to connect to an NFS share. The Docker Compose file has been parametrized to use, potentially, other drivers but the only one I have tested is “rancher-nfs”
You can locate the deliverable for this sub-project inside my overall Rancher catalog extension repo.
You can watch a distributed deployment in action in this short video.
Overall challenges and issues
Throughout the project I came across a few challenges. I am going to mention some of them here mostly for future reference by keeping a personal track of those.
- Even small things can turn into large holes. Sometimes it’s a cascading problem (i.e. to do A you need to do B but doing B requires you to do C). A good example was the Rancher sidekick requirement to be able to perform a volume_from. That basically broke entirely name resolution (see the single-host section for more info re what the problem was)
- Containers coming up “all green” doesn’t mean your app is up and running (properly). There were situations where containers were starting ok with no errors but I couldn’t login into harbor (due to certificates mismatches generated by running multiple instances of the install wrapper). There were situations where I could login but couldn’t push images. And there were situations where I could push images but the UI couldn’t show them (due to the registry container not being able to resolve the ui container name because of the name resolution issues with sidekicks)
- Debugging containers in a distributed environment is hard. At some point I came across what seemed to be a random issue to later find out that the problem was due to a particular container getting scheduled (randomly) on a specific host that was mis-configured. Fixing the issue was easy once this was root-caused. Root-causing was hard
- Knowledge of the application internal is of paramount importance when packaging it to run in containers (and, most importantly, to orchestrate its deployment). One of the reasons for which I left all named volumes connected to all containers in the distributed scenario is because I am not 100% sure which container reads/writes from/to which volume. Plus, a thousands of other things for which not knowing the application makes its packaging difficult (particularly for debugging purposes when something doesn’t work properly). All in all, this enforces my idea that containers (and their orchestration) is more akin to how you package and run an application Vs how you manage an infrastructure
- While container orchestration is all about automation and repeatable outcomes, it’s also a little bit like hand-made elf art. There was an issue at some point where (randomly) the proxy container would only show the nginx welcome page (and not the Harbor user interface). Eventually I figured that restarting that container (after the deployment) fixed the problem. I thought this was due to some sort of start up sequence. I tried leveraging the “depends_on” directive to make the proxy container start “towards the end” of the compose up but that didn’t work. It seems to work consistently now by leveraging the “external_links” directive (which, in theory, shouldn’t be required AFAIK). All in all being able to properly orchestrate the start up of containers is still very much a working in progress and a fine art (apparently since 2014)
- Managing infrastructure (and services) to run containerized applications is hard. During my brief stint into leveraging something simple like the basic Rancher NFS service, I came across myself a few issues that I had to workaround using different levels of software, different deployment mechanisms, etc etc. Upgrades from one version of the infrastructure to another are also very critical
- Another NFS related issue I came across was that volumes don’t get purged properly on the NFS share when the stack is brought down. In the Rancher UI the volumes seem to be gone but, looking directly at the NFS share, some of them (a random number) seem to be left over in the form of left over directories. I didn’t dig too deep into why that was the case
Conclusion
As I alluded to this is a rough integration that, needless to say, can be perfected (euphemism). This was primarily an awesome learning exercise and future enhancements (e.g. integration with the Kubernetes scheduler in Rancher, enabling the https protocol, etc. etc.) will allow me to stretch it even further (and possibly making it more useful).
An exercise like this is also very useful to practice some of the challenges that you could come across in the context of distributed systems with dynamic provisioning consumed via self-service. Sure this was not super complex but being able to get your hands dirty with these challenges will help you better understand the opportunities that exist to solve them.
As a side note, going deep into these experiments allows you to appreciate the difference between PaaS and CaaS (or, more generally, between a structured approach Vs an unstructured approach, if you will).
With PaaS a lot of the design decisions (particularly around scheduling, Load Balancing, name resolution etc) are solved for you out of the box. However, it may be the case that hammering your application to make it fit a distributed operational model may not work at all or it may work in a too opinionated and limited way. With an unstructured approach (like the one discussed in this blog post) there is a lot more work that needs to be done to deploy an application (and there is a lot more sausage making that you get expose to) but it can definitely be tailored to your specific needs.
Massimo.