DevOps (for Dummies)
Last year I wrote a blog post whose title was "Cloud Native Applications for Dummies" that was apparently well received.
On the same line, I'd like to do something similar for the average Joe when it comes to DevOps (whatever that means). The CNA post was about the taxonomy of a cloud application. This blog post is all about how organizations make that happen (operationally), if you will.
If for Cloud Native Apps the mantra is the The Twelve-Factor App manifesto, for DevOps I had to pick something else. And I am picking this quote:
"You build it, you run it".
DevOps is still quite an abstract term as it may mean a lot of different things to a lot of different people but I think that the quote above is where consensus is (today) re what DevOps, essentially, is.
There is also a lot of confusion opinions around sub-terms that we have seen emerging in the last few years (e.g. NoOps) that are somewhat related to DevOps. In this blog post I will try to describe what (I think) is going on without trying to religiously shove a particular naming convention down your throat.
Once you "get" the picture (well, my interpretation of the picture), how you frame and name it, frankly, becomes irrelevant and it's not my business.
Introduction
DevOps has often been pitched as "more empathy" among all people working across different layers of the stack. In addition, DevOps has always been pitched more as a cultural change than "you are doing DevOps if you are using tool xyz".
This is all true but yet it leaves the average Joe with a sense of "ok, so what? what does that even mean?".
I also believe that the intersection of DevOps and the growing success of (public) cloud has introduced some interesting spins to the concept of "Devs should work closely with Ops". It's not like "Devs" in your organization are working regularly and closely with (say) the "AWS" Ops people. More on this later.
So let's see how the "stack" (not just the software stack, but also the people chain) is changing in the context of DevOps and the mantra "you build it, you run it".
This is where the
The current state of the art of "Enterprise Private Cloud" adoption and consumption (how I see it anyway) is summarized in the slide below:
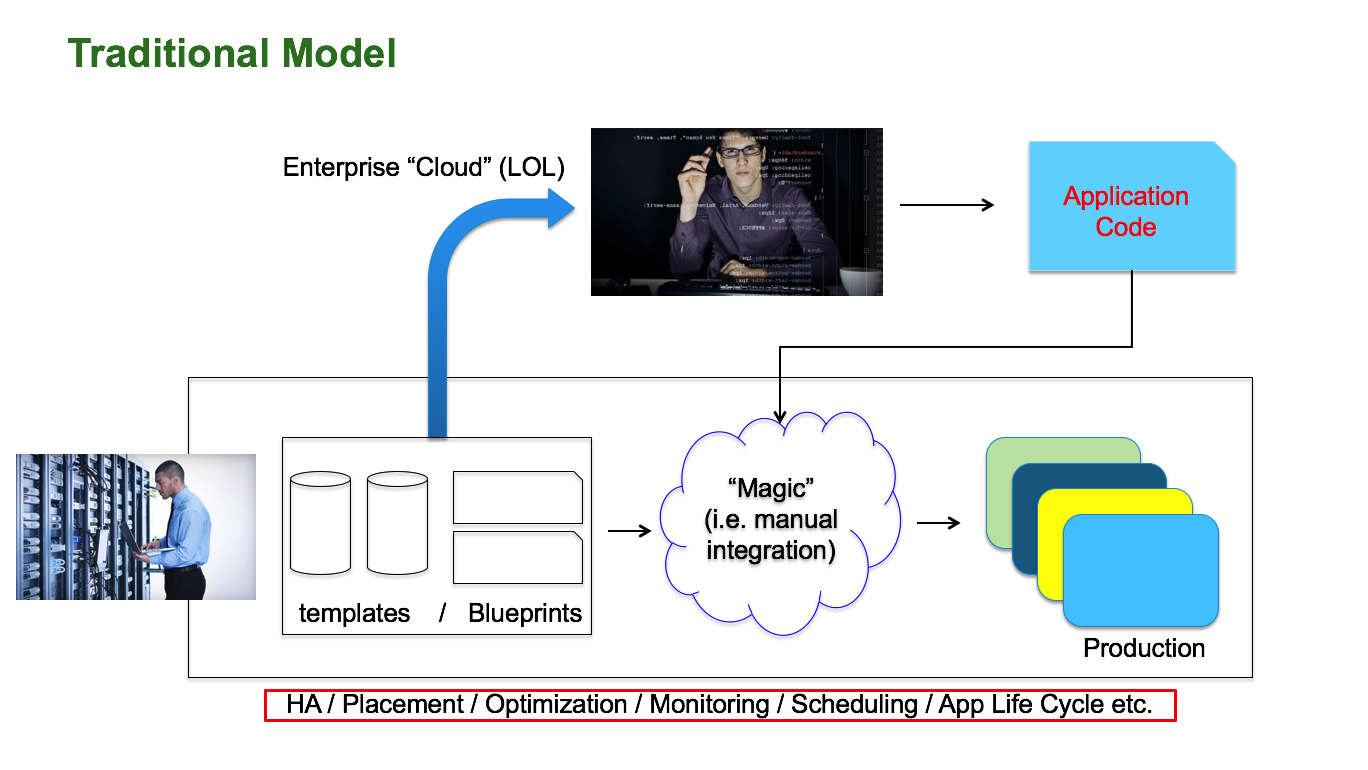
We can stay here debating this for hours but, long story short, Enterprise Private Clouds have been (largely) useful to provision resources for developers to work in Dev/Test environments.
What happens next between that and production is what I define "where the
I can hear three readers claiming "this is not true, we go all the way to production with our cloud". Fair enough, be proud of yourself as you are part of a small club (0.3-ish%) among all the organizations out there.
There is probably an infinite number of shades of gray but it often goes like this: there is a team (most often IT) that operates a private cloud infrastructure that allows developers to check out (in self service) resources that they use for test and dev. In addition to that the central organization provides "blessed" building blocks (often VMs with selected Operating Systems and / or standard middleware). Some IT teams push the bar as high as creating "blueprints" that puts lots of constraints on what the developer can do (in other words the power of the central organization dictating the "standards" and the need for "being compliant" are very strong in these contexts).
In addition to all this, the infrastructure layer (and the traditional Ops team) is also responsible for providing high availability services, workload placement, optimizations, monitoring, scheduling and all in all the entire application life cycle.
The way code gets from the hands of the developer into production varies depending on the organization's processes but it often involves some "magic" which is usually a lot of manual integration, ad-hoc and very labor-intensive tasks.
That's where the
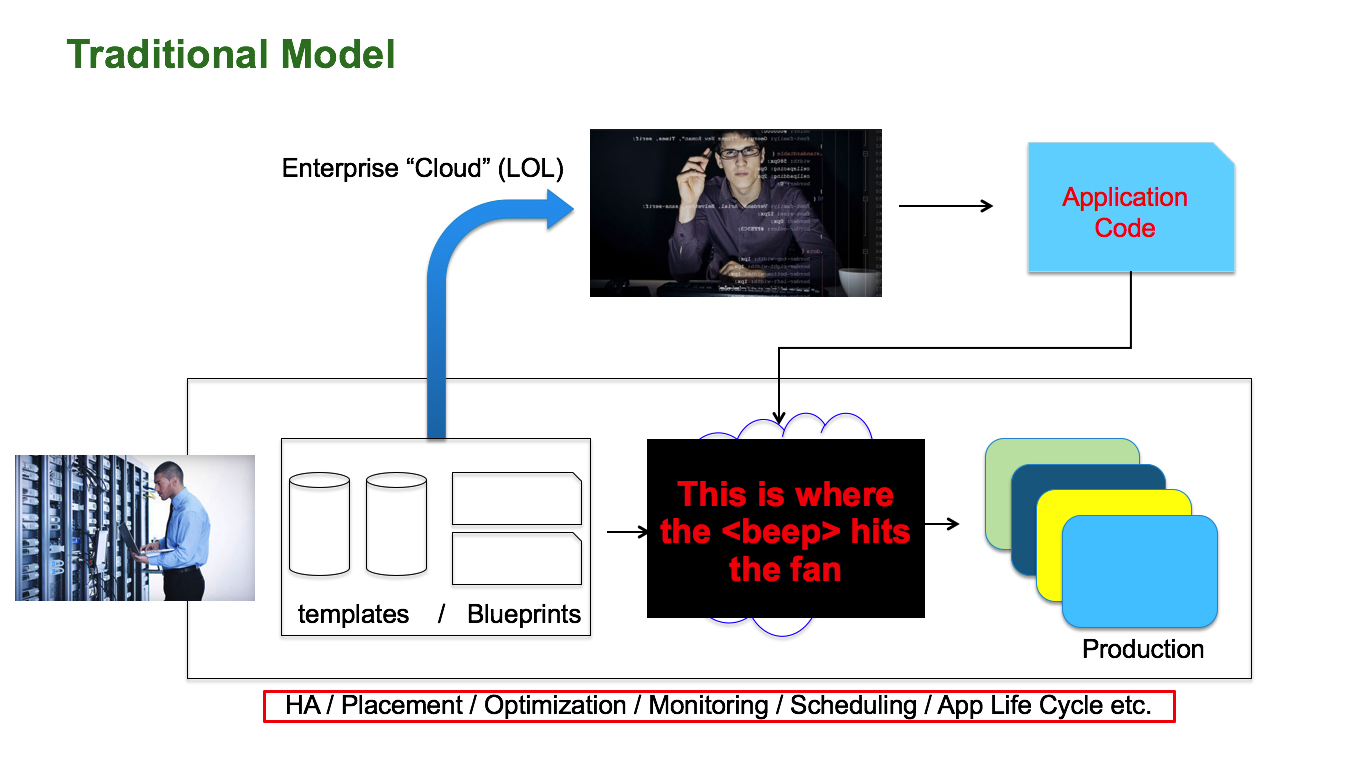
These are some examples of the interactions that you may hear between the devs and IT in a context like the one I have described above:
- IT (on the phone): “We won’t deploy your code in prod until December. What? Yeah I know it's August and so what?”
- IT: “What? You used Weblogic ver x.y.z.a.b.c? Sorry we only support x.y.z.a.b.d”
- Dev: “The App is slow? I have no idea, talk to IT. They own it”
- IT: “The App is slow? CPU usage is just 20%. It must be an app bug, talk to the dev”
- IT: “It will take 5 days to deploy it. It’s a hard task with a pretty big run-book”
- IT: “It will take 5 days to deploy it. It's an easy task but John is very busy”
That's pretty much the world we are in right now. On average of course. But maybe you are lucky and you are part of that 0,3% that does this better?
So what's DevOps then?
The world we are being catapulted into is totally different. This world is not just heavily automated but there is also an interesting morphing of roles that needs to happen (and is happening).
If you ask 100 people you will get 100 different views of the world, so I am going to offer mine here. Note that from now on the discussion may start to become a bit more subjective (to my understanding and experience). The discussion above is arguably more objective.
The first tenet of this epic shift is that organizations will (or should) draw a clear line between IT resources / capacity required (provider side - aka raw IaaS) and what people can build leveraging those resources (consumption side). This has a couple of side effects:
- decoupling the capacity from the tooling and techniques associated to consuming that capacity will allow organizations to more seamlessly source physical raw resources from either public or private cloud environments.
- doing so will help creating a very clear (and API driven) contract between the provider and the consumer. This is a must-have to introduce automation and remove the requirement for manual provisioning and configurations.
The second tenet of this shift is a complete reorg of roles, tools and processes to how application code gets deployed and operated. Sorry to rain on the parade but… you don't do DevOps just by claiming you hired the "VP of DevOps".
DevOps is a gigantic shift of responsibilities (both from a job role as well as from a technology perspective) to the upper side of the stack.
Closer to the developer and ultimately closer to the business.
This also has a number of (positive) implications that we will touch upon later but, before we dive deeper into this, without any further ado this is how this extreme change looks like:
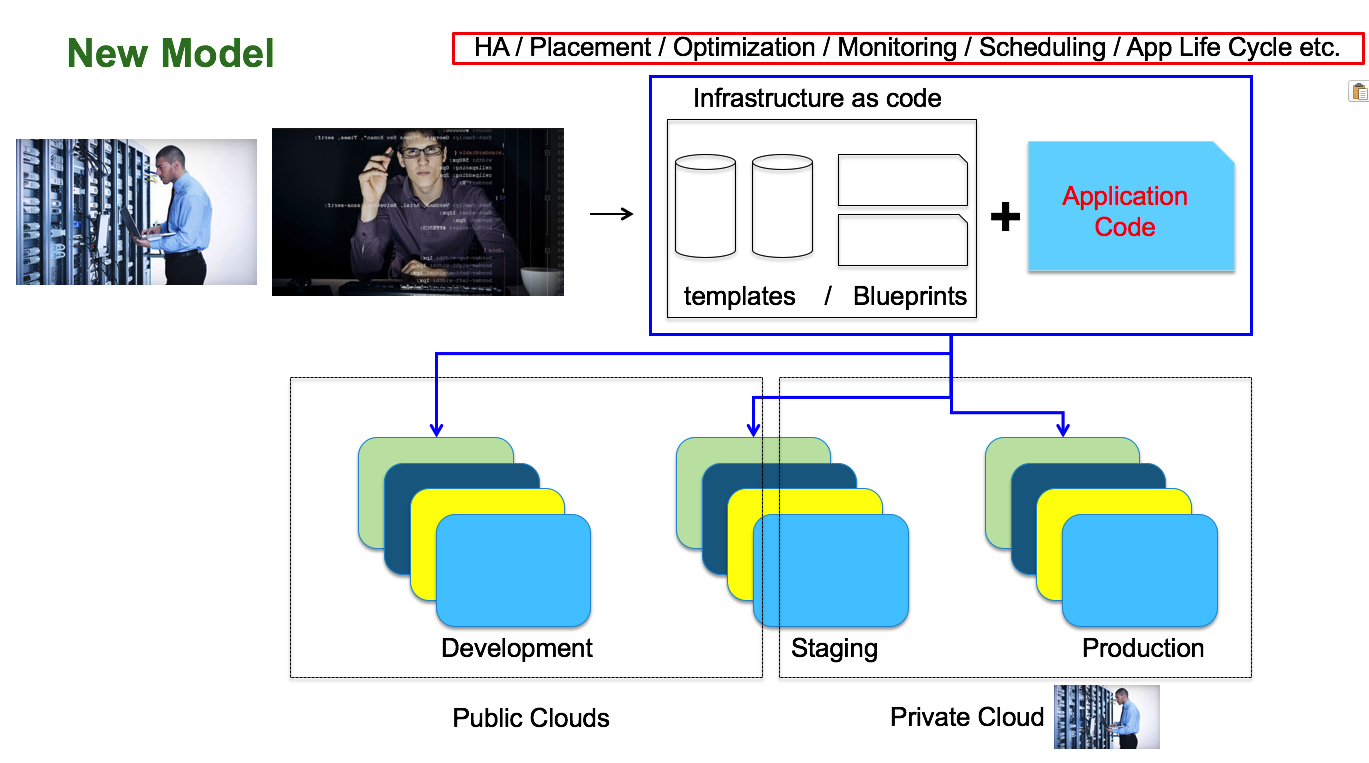
Look at how the landscape has vastly changed. Let's start from the bottom.
As we said, raw IaaS capacity could come from either a private cloud or public clouds. These are core infrastructure resources (aka "just enough infrastructure") pieces. Per Cloud Native Applications patterns these resources could and should be ephemeral (for the most part). There is a persistency layer component but we are not going to discuss it here (we will try to keep this discussion more around software life cycle, and not so much about how to persist data - which is another gigantic problem of its own).
First and foremost: if you work in (very) core IT at a company that is embracing this model (and you have a mortgage) you need to think about this: your competition (i.e. the AWS Ops guy looking after the EC2/VPC services) is only 0.0002$ away from stealing your job. Of course there is more than "cost" for not going off-prem but it's good food for thoughts, in my opinion.
The interesting part now happens above that layer. This is where now everything happens: from application development all the way down to actually running your applications. Remember the mantra? "You build it, you run it".
This is where everything gets codified including how you are deploying your code onto the "just enough infrastructure" we discussed above. This is where all the plumbing (i.e. infrastructure components including network, security, instances, storage, etc) gets configured. This "infrastructure as code" gets saved into a version control system (e.g. GitHub) so that you can keep track of (and revision!) it.
Your (infrastructure as) code becomes your documentation. You can then use this to deploy your actual (cloud native) application code into the various test, staging and production environments. As you can see there is no longer any
We will not get into much details but automating application code testing is of paramount importance in this context as the idea is that everything happens automatically. When a dev person checks in the application code the "platform" (that automates the magic) is able to trigger all the processes that take that source code all the way into production (eventually). If you have ever heard terms like Continuous Integration, Continuous Delivery and Continuous Deployment... they basically refer to the application code being automatically (and "fluently") integrated, tested and eventually deployed in production.
In order to accomplish this state of the art... a new model, new processes and new roles (and yes, incidentally new technologies) need to emerge.
As the "upper side of the stack" is now responsible for a lot more than just application code development, a new class of people that is able to bridge the gap between "pure coders" and "rack mounters" (ok, I am exaggerating but you get the point) needs to emerge as well. These people will work together (tightly coupled) with the traditional app developers and consume resources coming from either a private cloud or public clouds. If consuming local resources, these people and core IT will work via API interfaces (in a loosely coupled manner).
In this upper stack there is only one rule: “That’s not my job” is not something they are prone to saying (I don't remember where I read it but it capture the DevOps sentiment perfectly IMO).
You can call this duo in the upper part of the stack DevOps if you will (people with dev responsibilities and people with more ops oriented responsibility working as "one team"). I have seen people referring to these people as NoOps when organizations ditches entirely private cloud deployments (very common with startups) and only consume public cloud resources. I guess they talk about NoOps to underline the fact they don't have very core IT personnel running gears on prem. I (for one) usually stick on calling these people DevOps regardless of where they are sourcing the capacity (considering also that if you're scripting the deployment of an AWS VPC or things like that you are doing some sort of Ops anyway).
But again, finding the proper naming convention isn't my objective here. I just wanted to give you an idea of how the new stack (and new roles) looks like in this "new world". Also consider the role definition in different organizations will necessarily be somewhat blurry as they will find their internal equilibrium. All in all (and to dumb it down a bit - perhaps oversimplifying it too much) it's fair to say there will be, going forward, 3 major buckets / roles:
Role A - core IT: this is the person responsible for providing core capacity from your private cloud infrastructure (this role becomes optional if you go all-in with public cloud).
Role B - The Ops in DevOps: this person has secondary responsibility for understanding how the code works and prime responsibility for defining the proper processes to run it in all environments including production.
Role C - The Dev in DevOps: this person is responsible for writing the application code as well as for understanding the life cycle of the code (including supporting the code in production if need be).
As I said this is just a very approximated and high level characterization. Every organization will find their own fine roles definition. This will boil down to a number of organization characteristics the most important of which may well be the size. I can see an organization having a team comprised of 1 person (that does both B and C as a one-man-show) or a slightly bigger team comprised of, say, 8 people (where there will be more specialization across the B and C roles).
Unstructured Platforms Vs Structured Platforms
So who is building this "platform" (that does the magic) that lives in the upper level stack? I heard once Adrian Cockcroft mentioning that if you don't buy a platform to run cloud native applications, you are inevitably going to build one. I think that's pretty accurate.
There are a couple of philosophies that are emerging for operating cloud native applications. These two trends are referred to as "Unstructured Platforms" and "Structured Platforms" (aka "Opinionated Platforms"). There is a great article on wikibon that talks about this; my objective for this post is to dumb down a bit those concepts so that everyone could understand them.
In the former approach (Unstructured) role B (primarily) and C stitch together 23 different technologies that they pick from a list like this and build a "system" that allows them to automate pretty much everything from the git commit all the way to running application code in production.
In the latter approach (Structured) organizations will look into sourcing a black box solution that implements the entire "platform" (so to speak) out of the box without having to spend time stitching together 23 different technologies themselves. Examples of such black boxes are Pivotal CloudFoundry and Apcera.
This Structured model to me is more akin to a traditional "Enterprise" approach and as such role B may be even more so in charge of the black box (perhaps even in partnership with role A) while role C may enjoy more freedom of developing code and pushing it into production without having to deal too much with "DevOps" details.
I am not trying to say one approach is better than the other. I am just trying to lay out the two very different school of thoughts you may cross when talking about this stuff. The advantages and disadvantages of these two approaches boil down to the usual "build Vs buy" discussion.
Don't public clouds already offer lots of those platform services anyway, you may ask?
That is absolutely true. If you look at the like of AWS or Azure, they do indeed provide a lot of the services (out of the box and often for free!) that you would need to create a "platform" as described above.
This is "good" because you are half way through (if not more) and you don't have to choose among the dozens of available solutions. In addition, the public cloud provider will operate the platform services for you (something less to think about!).
On the other hand this is "bad" because, usually, those higher level platform services are restricted to use their very own raw cloud IaaS core resources. In other words you won't be able to use the like of CloudFormation to drive the deployment of a stack on Azure (or viceversa for that matter).
This is the same, usual, boring story of trading off freedom of choice for getting a native experience out of the box. Choose your poison, my friends.
There is a school of thought (or rather a tools vendors strategy?) that suggests to use and leverage just the core IaaS component of multiple public cloud providers (including your own private cloud) and run / own your own DevOps magic (either Structured or Unstructured). It's a bit of additional work for you and in return you get the flexibility to choose your resources and capacity end-point(s).
As an example, I have just come across this interesting article where this user explains how he evaluated Google Kubernetes Vs AWS ECS and this is what he had to say in the "Cloud Agnostic" section:
"There’s no real competition between the two here 🙂 ... ECS will always be exclusive to AWS. If you build your infrastructure around ECS and would like to move to another cloud provider in a year, you will have a hard time.
Kubernetes is cloud agnostic. You can run your cluster on AWS, Google Cloud, Microsoft’s Azure, Rackspace etc, and it should run more or less the same. I am saying “more or less” because some features are available on certain cloud providers and some are not. You will still have to make sure your new cloud provider is being supported with the features you use in K8s, but at least such a move is possible."
I am sure there will be people out there that have chosen ECS (Vs Kubernetes) but I found this article interesting because it was mapping exactly the point of the two school of thoughts I was alluding to.
Microservices (and containers)
What do microservices (and containers) have to do with all of this? Well, first and foremost if you embark into such a journey, you'd better break down that 500GB application monolith if you (really) want to have a team of developers that is responsible to develop, deploy, run and support their code in production. You want to create loosely coupled islands of interconnected modules so the contract between the various Dev(Ops) people is going to be the API interfaces they expose (and not the code they developed that execute said service). So in the end your developers will be organized in smaller, loosely coupled team that are going to be responsible for a specific module of the entire application. This is what I referred above to as "microservices teams". Sometimes these teams are also referred to as "pizza teams".
While there is no particular technology reason, containers (in general) and Docker (in particular) are becoming one of the tools of choice for packaging those (micro)services. In a way it makes sort of sense because (traditional) VMs are more geared towards larger and more stable (aka traditional) workloads whereas for an environment where the code churn rate is very high (due to frequent updates) you want to have something that is:
- small in size
- easy to package
- easy to share
- fast to start
- portable across different infrastructures (on-prem and off-prem)
VMs are great for an infinite number of use cases but are often weak when it comes to these characteristics. Containers seem to be a more sensible choice in this regard.
I will stay away (for now) from the discussion of whether you should run containers on bare metal or on top of VMs. This would require a blog post of its own to discuss. Steve Wilson has a very good set of slides on the topic that are well worth a read if you want to form an opinion of your own. Also consider this curveball / trailer: what if you could get containers that are in fact VMs?
It goes without saying that the industry is full of people very opinionated on the subject. It's sometimes fun to watch them fighting over Twitter during weekends. Warning: it's often difficult to separate the signal from the trolling noise.
Conclusions
The purpose of this post was to dumb down what's happening in DevOps land. I hope that it came across that this is not (just) a technology discussion. This is (primarily) a roles and organizational discussions. As a matter of fact the technology discussion is just related to the tools you decide to pick (which, in the larger picture I tried to describe, seems to be the less exciting part to be honest).
As always, if you are in core IT, I suggest you keep an eye on how this all is evolving because it may be disruptive for you and your job.
Interesting times ahead for sure.
If you have read this to this point, thanks (and congratulations).
Massimo.