What do Cloud Native Applications Have to do with Cloud?
A few weeks ago I wrote a post whose title was Cloud Native Applications (for Dummies).
While I don't want to claim that that was my masterpiece, I have received some positive feedbacks about it. So let's say we all agree on how a 'Cloud Native Applications' looks (or should look) like.
There are two major events that triggered this follow up post.
The first one is that I have very clear in my mind the moment when I wrote, in my previous post the following: "What’s missing from this picture (among many other things) is the scalability nature of these two domains. This is another core tenet of a cloud platform that I am not focusing enough in this post. Both environments can naturally grow and shrink based on external triggers (such as a growing number of application users or a growing set of data to be managed). As a result the application owner will pay for the actual resources that are being used by the application".
I clearly remember that the reason for which I wrote that paragraph was because I was thinking 'geeee... I need to write something about cloud here cause what I am writing has zero to do with cloud'.
Weird feelings.
The second event was a tweet I saw a few days later that said:

These two events made me think.
What do so called "Cloud Native Applications" have to (really) do with cloud? The reality is that the answer to that question is... nothing, and I will explain why that is the case in my opinion.
Let's first agree on what cloud is and let's say that it's what the NIST says it is. Cloud is a 'thing' whose characteristics are 1) self-service, 2) Internet accessible, 3) multi-tenant, 4) elastic, 5) metered and paid accordingly.
What does this have to do with 'application architectures'? Little to nothing IMO. Ok, there may be some characteristics here (e.g. elasticity) that some new application architectures could benefit from but these are two topics that are largely orthogonal.
Let me explain what I think happened in the last 10 years that created a very strong bias on the way we think about this nowadays.
Roughly 9 years ago Amazon introduced their web services brand initially with S3 and shortly after with EC2. By doing so they have introduced a new IT procurement model that was based on OPEX and not on traditional CAPEX. Years later the NIST will codify this model in the PDF I have linked above.
At the same time, and in a total parallel universe if you ask me, Amazon also introduced a new application architecture paradigm that we refer today as 'design for fail'. There are books (and other blog posts) on this topic and I am not going to repeat myself. If interested, you can read some of those thoughts here, here and here.
'If you move to the cloud you need to do things differently', 'you can't bring your application as-is in the cloud', 'cloud has a different architecture compared to your traditional legacy data center', 'the cloud is a different place and you can't run your client-server application there'. These were (and still are!) some of the common stereotypes we hear from 'consultants' talking about 'the cloud' (whatever 'the cloud' is).
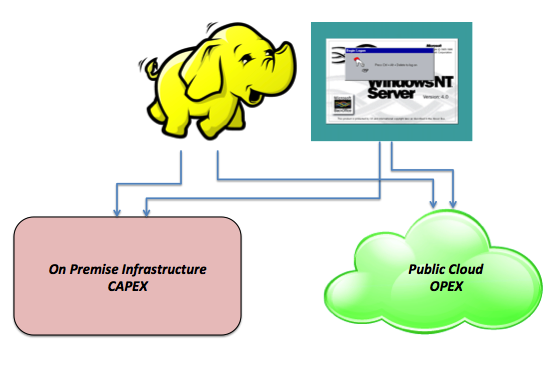
So we got accustomed to mixing these two different concepts (i.e. the IT procurement model and the application re-architecture model) as if they were one and the same. But they are really different things.
For example, I would like to be able to run Windows NT 4.0 for 14 hours for $1.36 (with an OPEX model on a public cloud). And I have done it!
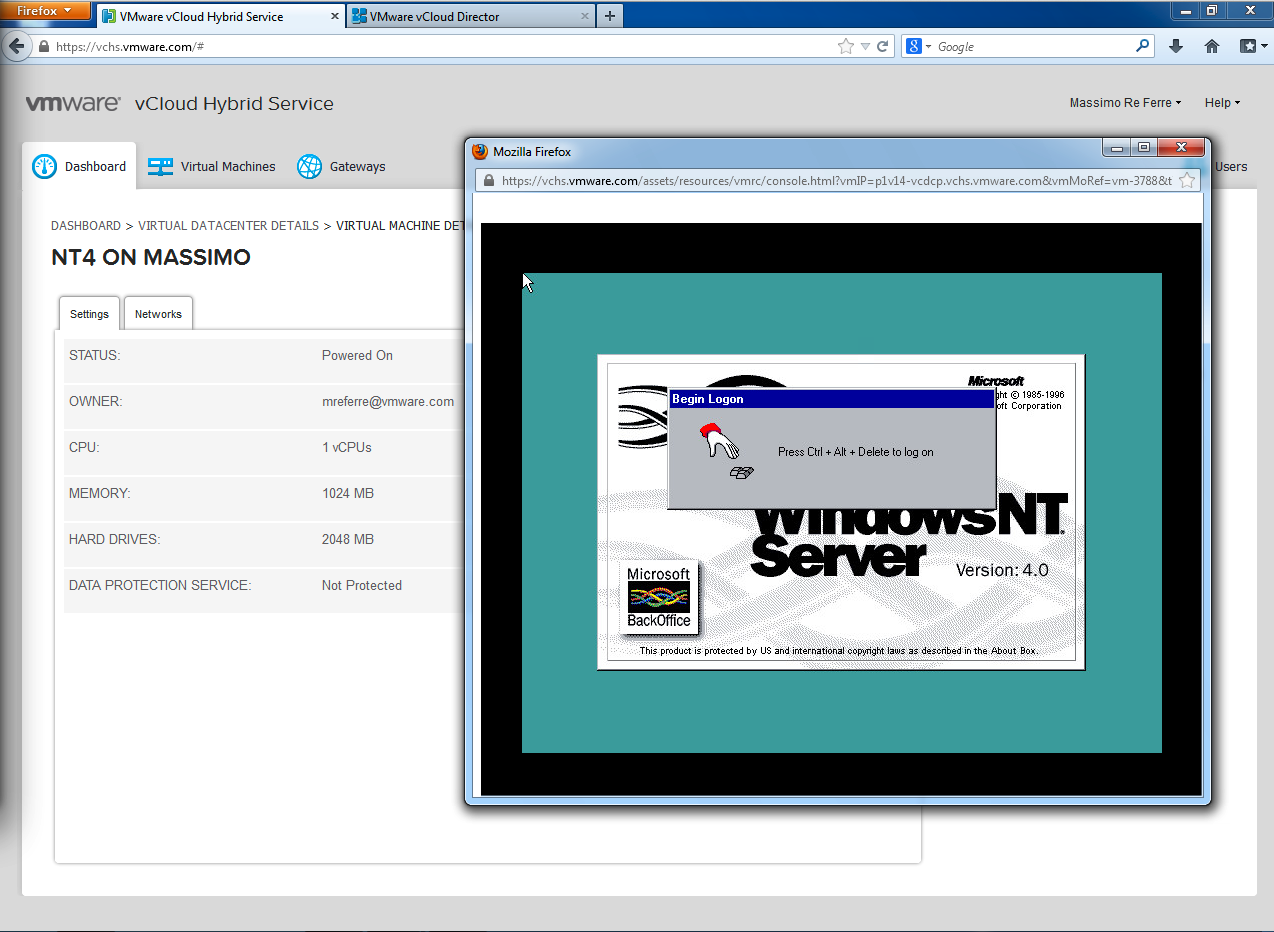
But I would also like to be able to run a next generation application like Hadoop (for lack of a better practical example, which I am sure you can think of many)... on a traditional, single-tenant and privately connected so called "virtualized enterprise infrastructure" (can it be less cloudy than that?).
And do this with a very traditional, on-premises, non-elastic and CAPEX model (no, most definitely cannot be less cloudy than this!).
But I have done that too! (Well, he has done that).
This truly is the essence of what I was trying to argue in my old Cloud Spectrum blog post.
I have to give credit to VMware (alert: I am a VMware employee so turn on your bias filter now) for having been the first vendor to challenge this notion that "in order to go to the cloud you have to re-architect your application". This is (to me at least) what this whole hybrid cloud thing is about: the ability to do what you do today (with traditional applications), with a different (cloudy) procurement model.
You may argue (it would be legit) that VMware has a vested interested in claiming this, but on the other hand one could argue (and it would be as legit) that Amazon has a vested interest in claiming that 'cloud' was all about architecting your application to fit their model.
But what we are discussing here is more than that. Not only you can run traditional workloads 'in the cloud', but you can also write next-generation applications and run them on-premises on a virtualized infrastructure that resembles nothing of a cloud. This is what drives the clouderati mad (among many other things that happened recently).
And by the way this doesn't even necessarily need to be 'VMware on-premises'. It could be anything that provides enough flexibility (and an API of some sort) to be able to automate the deployment and the management of your next generation application (per the taxonomy in my previous post).
Ok, I get that if you are writing a next generation mobile app and you are doing it right, a public cloud is the place where you can start small and grow big. However, if you are a more traditional Enterprise that is building next applications for internal consumption (or, anyway, for a consumption pattern that doesn't necessarily has 6B people as a target) does it really make any difference if you deploy it locally or in an 'elastic public cloud'?
I also get that some Enterprise customers are moving to the public cloud because in the public cloud they find services that would be either very difficult or cost prohibitive to build in house. But then again, what does this have to do with (next generation) application architectures? This is a typical build Vs. buy discussion (well, build Vs. rent in this particular case).
This is, IMO, what people would like to be able to do in the end:
And do so in the most transparent way possible (which is arguably a big challenge, let me tell you).
As a matter of fact, that tightly coupled relationship between the commercial model and the (next generation) applications architecture is decoupling right now.
Never mind me playing with NT 4.0 on a public cloud.
Look at what AWS is doing lately in terms of instance auto-recovery or in terms of on-line host patching maintenance. No more than 2 years ago they would have laughed at who suggested to provide resiliency at the instance level or to provide a way not to have planned downtime at the instance level. It's 'design for fail after all'. This is what drives the clouderati even more mad.
Today Amazon is delivering on what 2 years ago looked 'too legacy' for them to spend time on.
Perhaps because they realized there are more money to be made with 'NT 4.0' (and what it represents) than there are with 'Hadoop' (or what it represents). That is (or was?) the Amazon dilemma.
Anyway, I am digressing again.
All in all, I would just avoid calling 'cloud' something that relates to mere architectural best practices on next generation application design.
I'd rather stick calling 'cloud' an IT consumption model (regardless of the workloads being run on it).
Massimo.