T-Shirt Size Instances and Storage Management in AWS and vCHS
In the last few weeks I had lots of discussions with customers and partners regarding the concept of T-Shirt Size instances as well as the nuances of storage management in both AWS and vCHS.
In this post I'd like to touch on both. A similar (albeit not as detailed) discussion was included in the AWS and vCHS parallel session I presented at VMworld 2013. The content was somewhat controversial as you can read here and perhaps a bit misinterpreted (make sure to read the comments of that post as well).
Why am I writing this?
There are two main reasons for which I am writing this post.
The first one is to argue why I think the AWS T-Shirt Size concept isn't a "feature". I would like to demonstrate why vCHS doesn't need that. Ideally, the next time you start with "oh vCHS doesn't support T-Shirt sizing? How come? AWS does!" I can point you to this post instead of wasting 20 minutes telling every time the same story.
The second reason for which I am writing this post is to give you a sense of what I mean by hybrid cloud.
Most people tend to associate the concept of hybrid to the ability of configuring a VPN all the way into the public cloud or having a single "pain" (not a typo) of glass, which is oftentimes too high level, and even more often useless and expensive. These are all (somewhat) valid angles but to me hybrid can be much more.
It is the operational continuum of how you do things on-premise and off-premise. More on this later.
T-Shirt Vs. Tailor-Made
Without any further ado, this is one of the slides I used in my presentation to show how T-Shirt Sizing works with AWS.
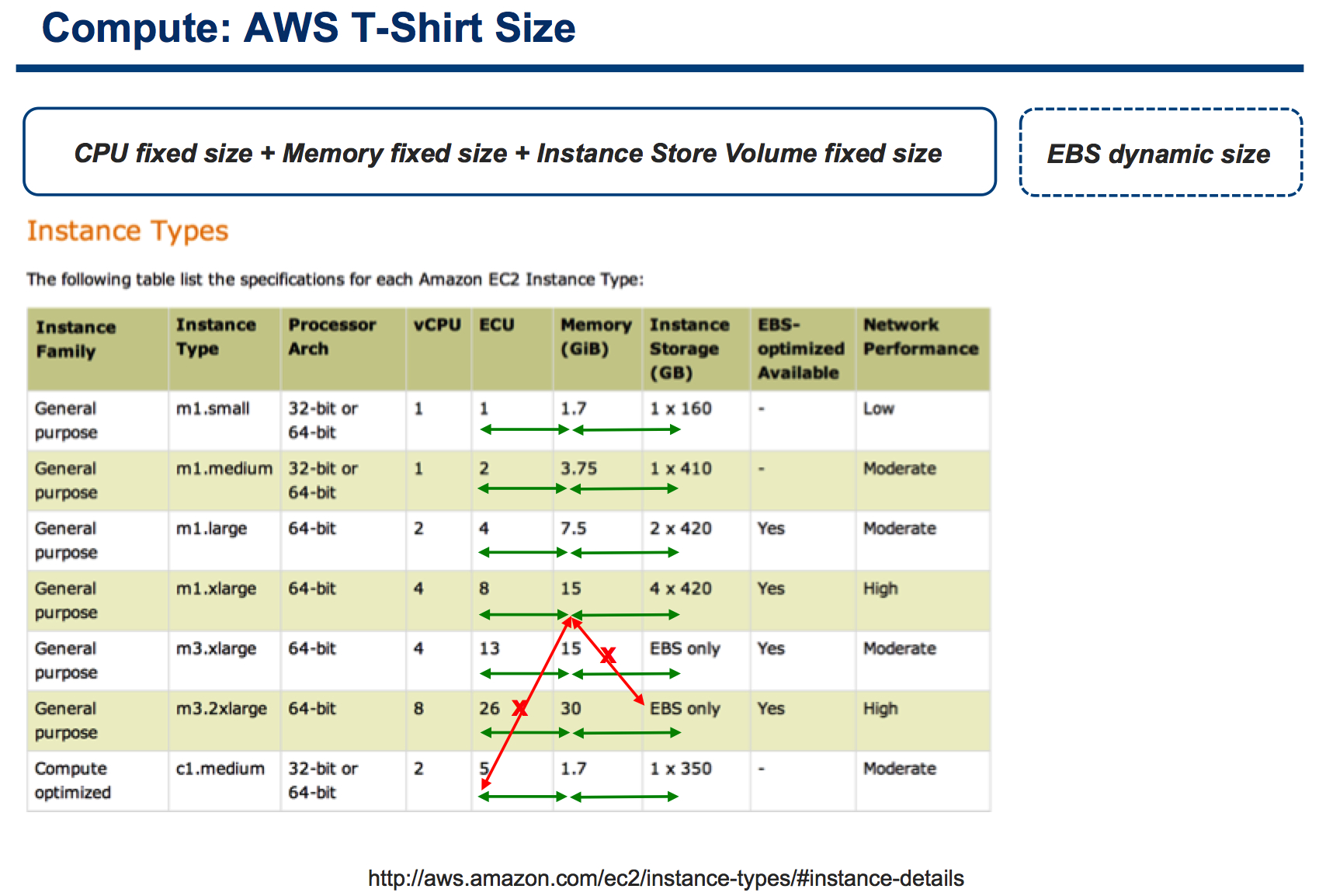
Allow me to over-simplify for sake of time. You can deploy a certain number of instance configurations in AWS and they are a fixed matrix of CPU, memory and (ephemeral) storage capacity. You can't mix and match at will.
For example, if you need 8 vCPUs, you need to get (and pay for) 30GB of memory. If you have an application that requires a huge amount of memory but could leave with half vCPU? Sorry, you can't do it.
Oh, and (almost) all of these instances include ephemeral storage: if you don't need it because you need to use persistent storage (common for existing traditional workloads and many application architectures), well it gets wasted. Sorry.
Sure there are memory, compute and storage "optimized" instances (to alleviate this problem) but yet they can't cover all potential combinations you may need.
Note: persistent storage (aka EBS) is not part of the instance configuration matrix as it gets configured separately, which is good. More on this later.
If you have been working in IT for a few years, you'll realize that this T-Shirt Size approach isn't how it's been working in the past. What you are (most likely) used to do is to right-size your VMs based on their application profiles and their actual needs. That's how it works with vSphere and, in turns, with vCHS.
As a matter of fact, when you deploy a new VM in vCHS this is how it looks like:
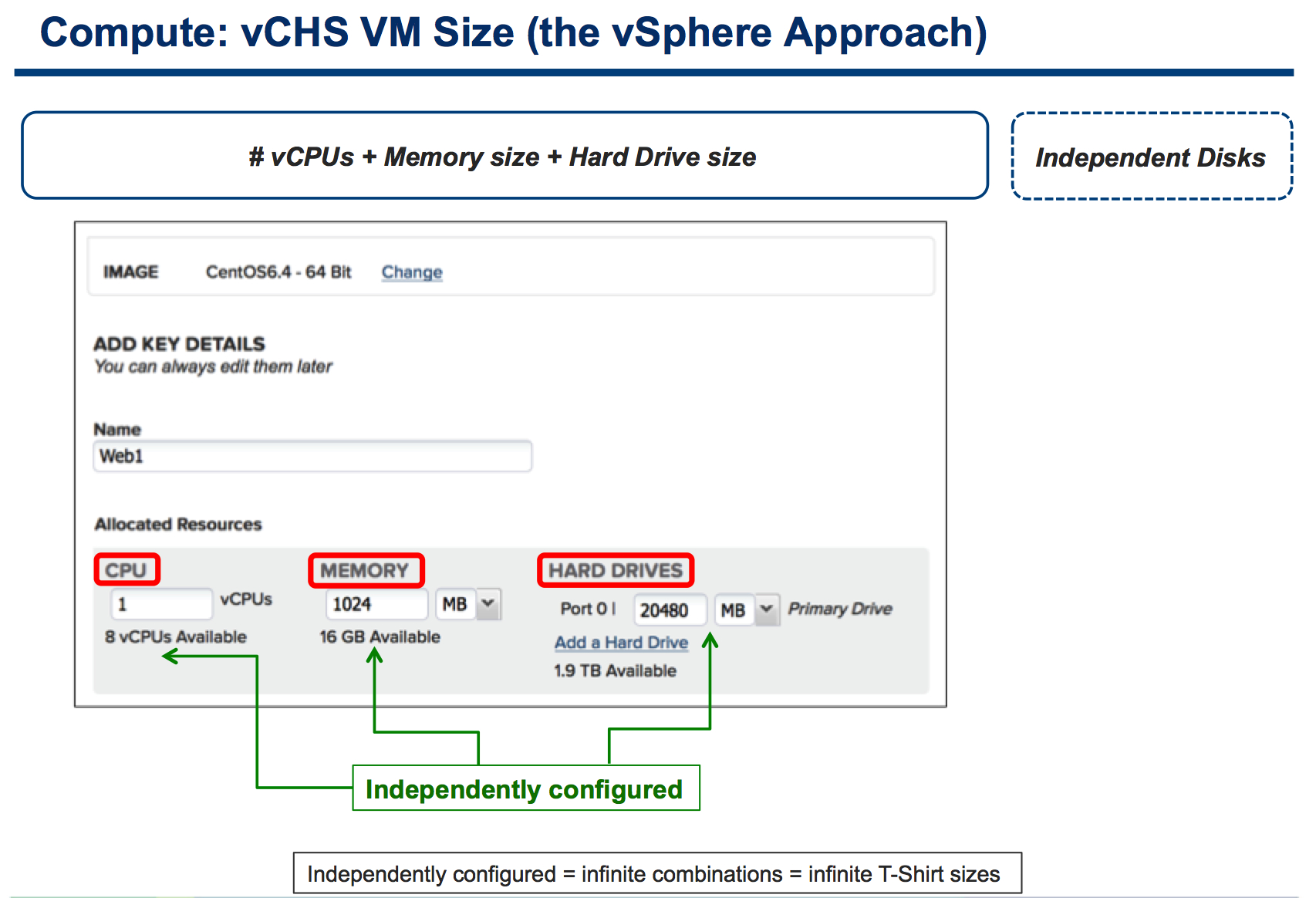
I guess the slide says it all but, essentially, you can configure your VMs with the CPU and memory combinations you need and want. Do you have an application that requires a lot of memory and close to zero cpu cycles? Sure. Do you have an application that requires a lot of cpu cycles and close to zero memory? Sure. I will discuss the storage aspects later on in this post. Hang on.
Note: this discussion isn't about absolute configurable numbers (which change often and not necessarily may see AWS at a disadvantage compared to vCHS), but it is rather about the flexibility of mixing and matching the configuration of these two subsystems.
Why is this ironic?
It is a well known thing (or at least a common understanding) that Amazon uses this fixed matrix technique to better use and allocate their physical servers. Since Amazon doesn't have (yet?) anything like vMotion or DRS they need to plan very carefully where and how they statically place workloads on "standalone" virtualized physical boxes. They can't afford to have un-balanced configurations running on their hosts because they would end up wasting resources and their "economy of scale" story would go belly up.
On the other hand vCHS can leverage all vSphere advanced workloads placing algorithms and optimize workload run-time location on-the-fly. This creates more flexibility (than what Amazon can achieve with AWS) and that flexibility allows users to pick their mix of configurations at will. The algorithms running in the back-end will take care of proper run-time placement regardless of the configurations of VMs.
This is where psychology comes into play and make all this so funny (or ridiculous).
The clouderati call the vCHS approach virtualization 2.0 implying it's "the old way to do things". AWS is now so "cool" that their advocates turned a necessary limitation of the service into a "most wanted" feature (or "the new way to do things"). And customers are all over it given the amount of "oh vCHS doesn't support T-Shirt sizing? How come? AWS does!" I hear every other day. Amazing!
Disk Management
In an attempt to not bore you to death I'll just say that I am focusing on the use case that requires disk persistency here.
While ephemeral storage and block storage (EBS) opens up a certain number of innovative use cases, I am going to focus here on the most simplistic and basic scenario of a user that wants to create a Windows instance/VM with a persistent drive.
vCHS doesn't have the concept of an ephemeral disk: all disks are persistent. In vCHS you just deploy from a template and the "Hard Disk" you configure (essentially a VMDK) will be persistent. Done.
In AWS you need to use an EBS to provide persistency. Amazon did a good job at creating a workflow that mimics how customers often deploy persistent VMs in a data center. This is somewhat similar to what VMware does with vCHS.
But the devil is in the (operational) details: let's say that, at some point of the life cycle of this instance/VM, you need to extend the size of the disk you configured. This is a very common use case. A quick search on Google let me pick, for example, a nice article from David Davis on How to Extend a vSphere Windows VM Disk Volume. That's how you often do it. On-line expansion of the disk with a click of a mouse. That's what IT users would expect.
Let's switch to the cloud now.
This is how you extend a disk of an instance on AWS: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-expand-volume.html
In short and in a nutshell:
- Stop the instance
- Create a snapshot of the EBS disk
- Create a larger EBS disk from the snapshot
- Detach the previous disk from the instance
- Attach the new larger disk to the instance
- Restart the instance
By no means this is the end of the world, yet it is clearly a departure from the operational model you are used to.
Regardless of whether that is vSphere or another enterprise context such as the on-line expansion of a logical unit of a physical disk array (SAN or DAS that is).
Now let's look at how you extend a disk of a VM in vCHS.
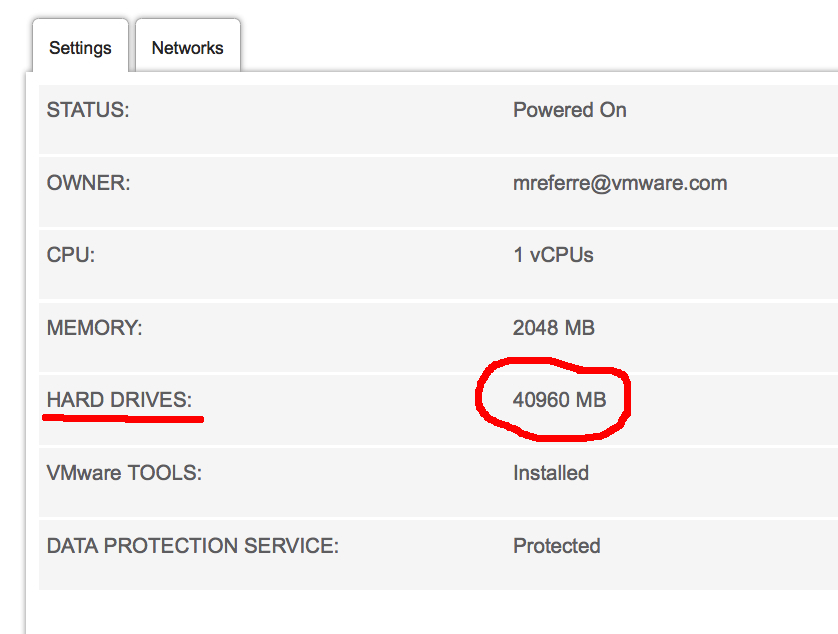
I have created a Windows 2008 R2 VM that has a 40GB persistent C:\ drive. This is what the properties of the VM on the vCHS portal look like:
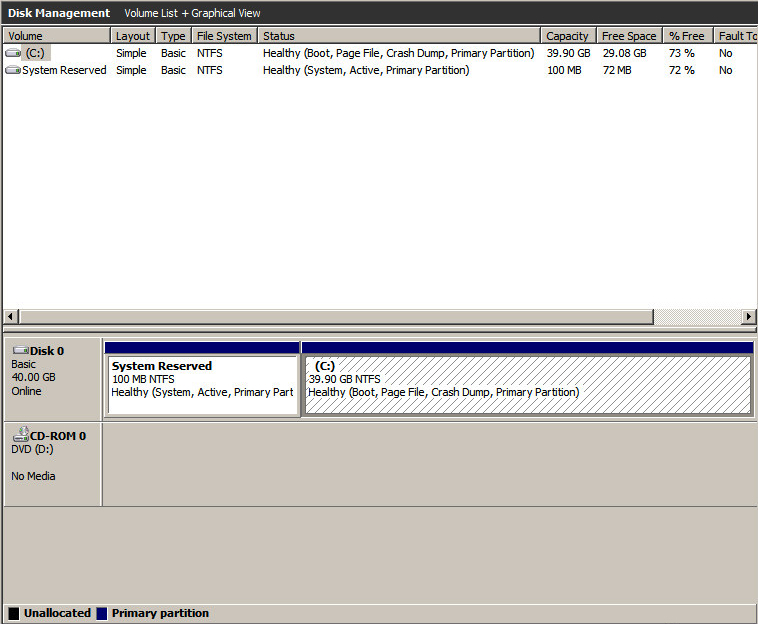
This is how the disk layout is represented inside the Guest OS. Note the 40GB C:\ drive:
With the VM up and running, you can go back to the portal and click on the hard drive.
A new window ("Change Hard Drives") pops up.
Here you can type the new size of the existing disk. In this case I need to add 20GB of disk space so I am entering 60GB (40GB existing + 20GB of additional space):
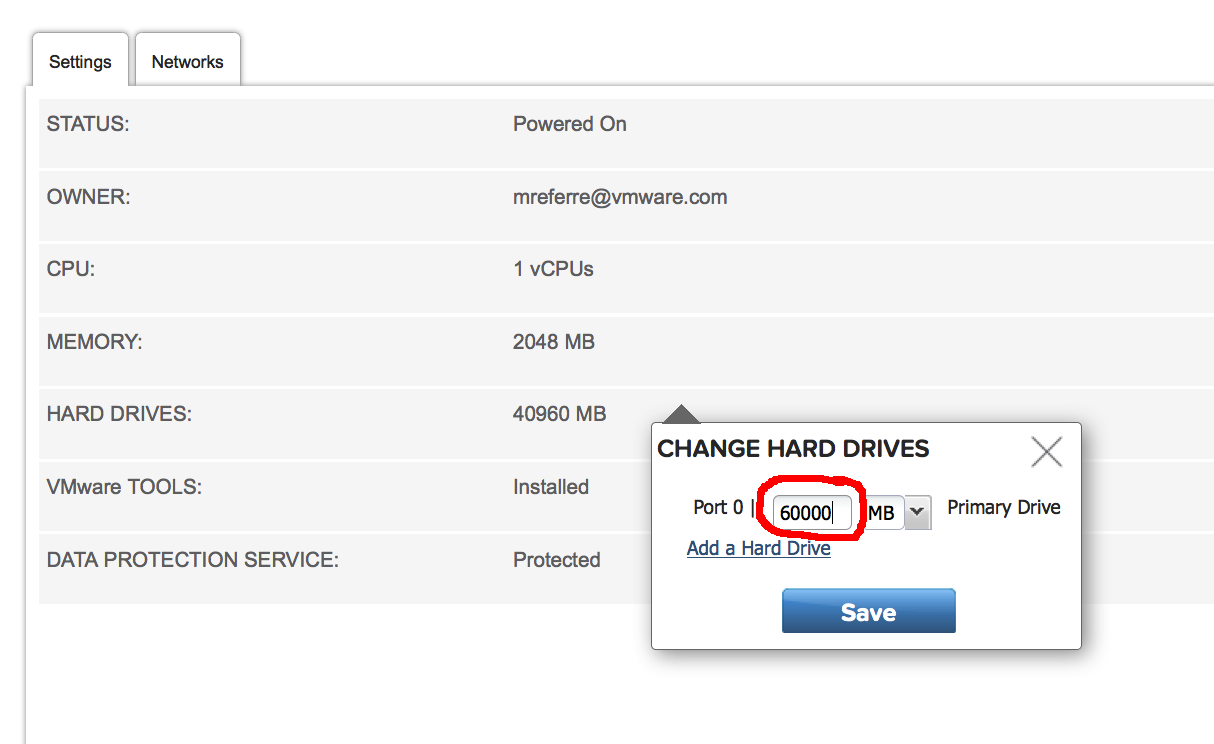
Click Save. You're done.
Notice the portal now says the disk size is 60GB:
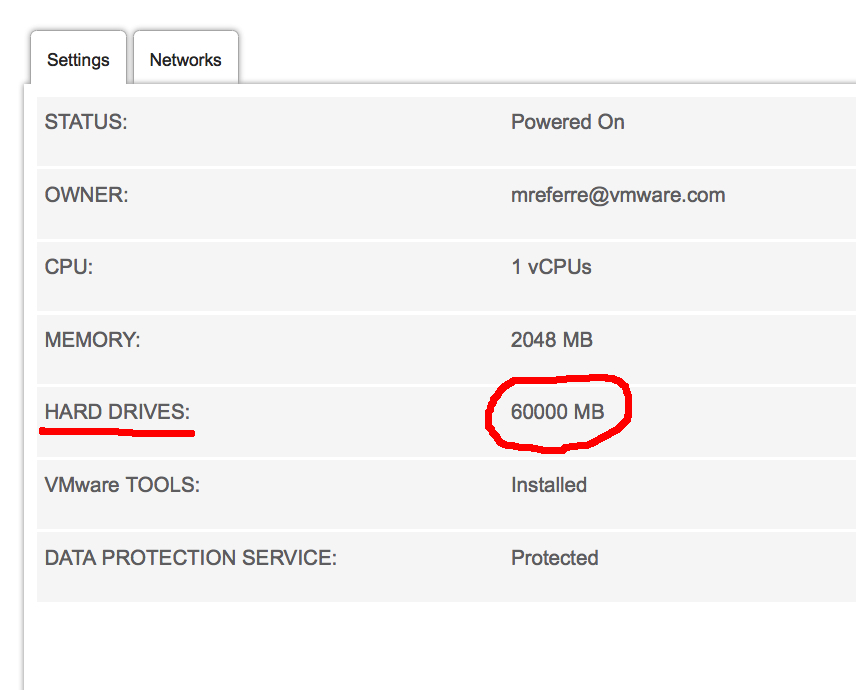
Note: if you have an inclination for APIs, you can do the exact same thing via the vCloud APIs as described at page 125 of the vCD API Guide.
If you go back to the in-guest disk management tool and rescan the disk subsystem (while the VM is still running) it will show the additional 20GB of free space I just added:
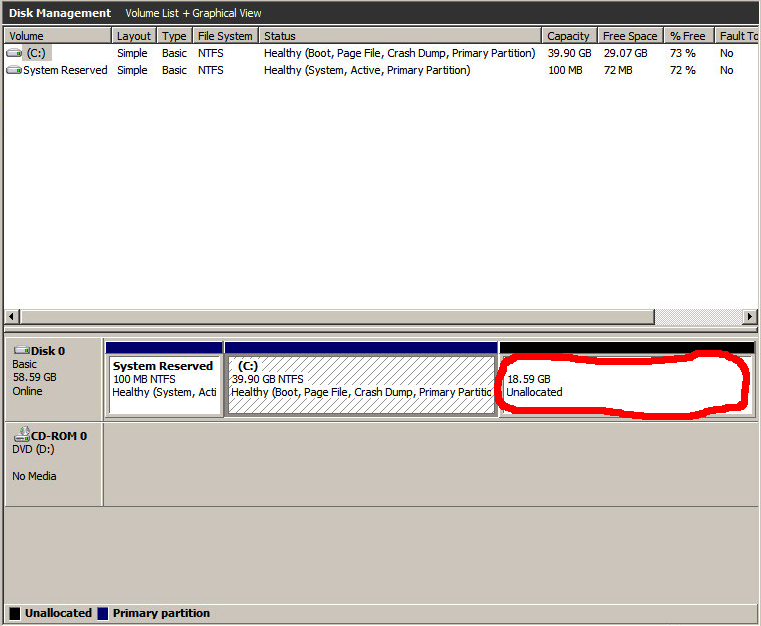
This is exactly where you'd be after following the much longer and articulated AWS procedure to expand an EBS.
Conclusions
The point of this post isn't so much to say that consuming vCHS is easier than consuming AWS. The point of this blog post is to underline that, whether it's the CPU, memory or disk configurations, vCHS provides a familiar operational model that most (if not all) IT people are used to.
One may also argue that vCHS has a better operational model compared to AWS (in the context of what I touched in this blog post, at least) but, you know... de gustibus non est disputandum.
To recap: no, vCHS doesn't need T-Shirt sizing and you can operationally consume vCHS the way you have enjoyed consuming vSphere in your data center. That's what I also mean by hybrid.
Massimo.