The Evolution of x86 Server Architectures
I spent a good 10 years of my IT career looking closely to hardware platforms (at IBM STG - Systems and Technology Group). After more than two years focusing purely on infrastructure software (at VMware) I thought I wanted to share where I think we are headed with the design of x86 servers. We all know x86 is eating away other platforms' marketshare. This shouldn't be a shocking news. I wrote about it when I was at IBM working on these stuff.
What's interesting, in my opinion, is how x86 is eating that lunch.
This discussion revolves around where value is being delivered by a given platform. Historically, in the non-x86 segment, the majority of the value of a given platform has always been delivered through hardware (or at the very least through a deep combination of low level software and hardware). I have always been floored by how much some people were missing the point when claiming that "an advantage of the Unix platform is that it supports concurrent CPU maintenance whereas an ESX server cannot do that".
That's how those systems (non x86) are being thought and engineered at their very inception so there isn't too much to say nor there is too much to talk about here. Take "one system" and build as much resiliency and reliability as possible into it. That's it. I don't see this trend changing any time soon.
In the x86 space it is very different: the design of those systems keeps changing over time depending on different input parameters. One of which is the morphing software stack running on top of that platform.
Let me start right away with the graphical representation of what I think it is happening in the x86 space. Note that many of the names there refer to specific vendor technologies. This is just because I am more familiar with those names than with others and there isn't a hidden message behind this. Whenever you read of a product name you should ideally put "kind-of-thing" next to it.
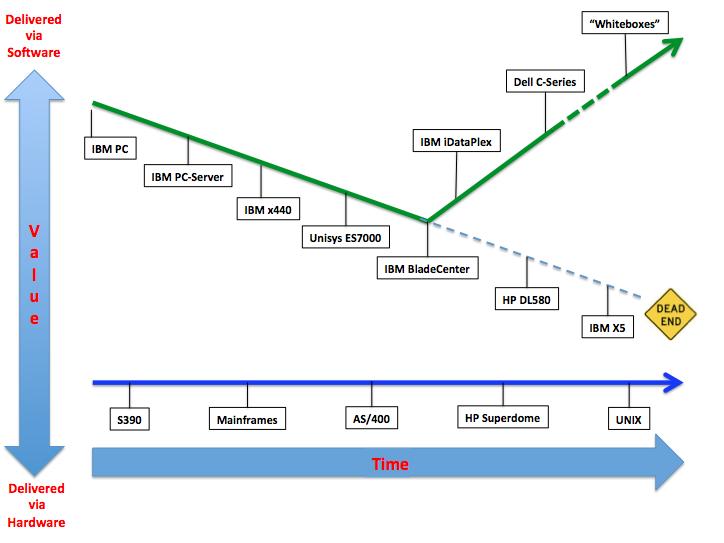
I see the x86 systems development a two-leg journey. The first leg is what happened circa during the nineties and early into the 21st century. Hardware vendors were all trying to turn PC's into very highly available and scalable systems. The objective was to make an x86 server look and behave like a Unix system (see above). The best example I can find for this trend is an IBM Redbook published in 2001 titled "High Availability Without Clustering". The relevant part of the abstract is copied below for your convenience:
"... When clustering cannot be justified, IBM xSeries and Netfinity servers offer many features, as either standard or optional components, that help to ensure that the server keeps running when subsystem components fail ... Advanced management features provide warnings and alerts of impending problems, allowing you to take preventative action before the problem affects a server's operation."
This was around the same time when the IBM xSeries 440 saw the light. At the same time Unisys was pushing their ES7000: a 32-way x86 systems dubbed as "the Intel mainframe". I believe that Unisys doesn't sell that "thing" any more at this point. Or at least I hope so, I am too lazy to check.
Than something happened and IBM introduced their first blade offering. I consider the IBM Bladecenter a cornerstone of the design of x86 systems. Not so much because of their form factor but because of the notion of a different type of scalability (Out Vs Up). This was such a hot topic back in the days that in 2004 I wrote an IBM Redpaper on the topic: "VMware ESX: Scale Up or Scale Out". Ironically, after 8 years, many of the considerations in it are still applicable.
This was the time when we started to discuss few big servers...
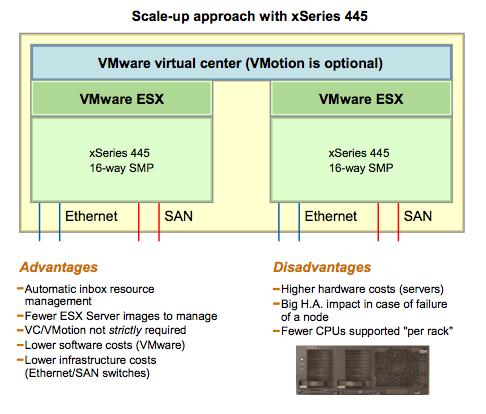
... Vs. many small servers:
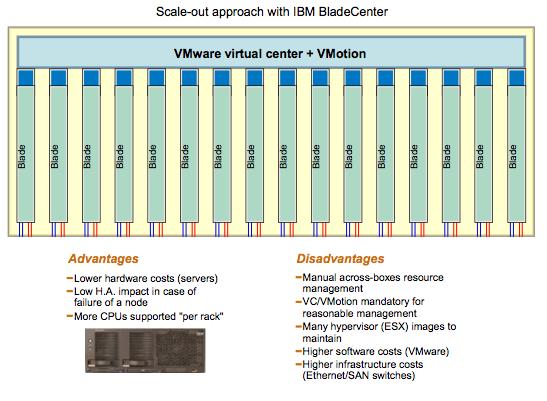
(I apologize for the quality of the pictures - if interested, download the PDF version at the link above).
It is important to notice though that, with the IBM Bladecenter, we were still in the first leg of the journey, meaning that those blades were still engineered with redundant components (at least the chassis was). Hardware failure was still not an option and components were redundant. Point in case was the first ever blade that was announced for the BladeCenter: the HS20 had a single drive and I can't tell you how much troubles that caused when talking to "traditional" customers that were used to a RAID1 setup in every single physical server "to protect the OS". The HS20 was clearly well ahead of its time.
The journey on that leg still continues nowadays with all vendors including HP, Dell and IBM developing reliable high-end x86 systems that scale up to 4 sockets (some systems apparently still scale to 8 sockets, for what it is worth). That dead-end sign you see on the slide may not happen any time soon but that trajectory is clearly not where x86 systems designs are headed to.
Where they are headed to is, in my opinion, towards the other leg of the journey. This is where the design of those systems started to take into account that more and more the value is now being delivered in the software stack. As a consequence of that, less value is required at the hardware level. Long story short, this means two major design shifts:
-
scaling up resources in a single server is no longer strictly required and
-
high availability at the single system level is less than a problem.
That's where the second leg of the journey starts and that's where some of the tier-1 vendors have started to invest in new x86 server designs. IBM iDataPlex and the Dell C-Series are two good examples of this relatively new design philosophy heavily geared towards design-for-fail type of infrastructures. The trend today is NOT so much about taking a single x86 system and try to make it as reliable as a Unix system. Rather, today the trend is to develop systems that scales out and are very efficient (especially from a power consumption perspective). The software stack will take care of combining those resources in a single gigantic virtual pool. In addition, the same software stack running on those systems, will take care of protecting (transparently) applications from the failure of one or more servers.
This may happen at different levels of the software stack (e.g. infrastructure software, middleware, application) but could require an entire post on its own.
Again, I am not implying this will happen anytime soon for the average company out there buying IT but this will inevitably lead to things like whitebox / home-made servers (ala Google) or Facebook's Opencompute initiative. This is initially very palatable for deploying large scale public cloud infrastructures but this design philosophy will inevitably be used by more traditional customers especially as the software stack they are using matures towards a more design-for-fail model.
I am not implying either that tier-1 hardware vendors will disappear, although those that are obsessed by "profit per single server" will take a hit. Those that are more willing to make money on "volumes" will have good chances to fight and possibly win this battle. It will be interesting to watch this space.
It's also important to note that the same concepts we have discussed here are also applicable to storage subsystems as we move away from high-end, scale up redundant boxes to more scale-out architectures most of the time based on x86 building blocks (either running as a separate infrastructure or on the same infrastructure that is running the workloads). Consider the following trends for example:
-
Many brand new high end storage servers are being built on x86 commodity parts Vs. proprietary hardware technologies (e.g. IBM XIV Vs. IBMDS8000)
-
Many modern applications do not even require shared storage. DAS (Direct Attached Storage) is becoming an option for those scenarios.
-
For those architectures that still require shared storage now there are solutions to turn DAS (Direct Attached Storage) into a * virtual SAN* (e.g. VMware VSA, HP Lefthand Virtual SAN Appliance)
Networking and security are on a similar path where hardware based systems are being replaced (or could potentially be replaced) by software based appliances running on x86 systems. Getting into the details of storage and network devices trends is beyond the scope of this blog post.
Now onto a stupid exercise as I close this post.
I have discussed many of these concepts in a previous blog post titled The Cloud Magic Rectangle (still one of my favorites). I thought that it would be interesting to (try to) map the software cloud products discussed towards the end of that post, with the trends in server technologies I am discussing here. Note that, to appreciate this exercise, you should first read that blog post.
Anyway, this is what I came out with for the "BIG 4" products:
This is how the overlay looks like for VMware vCloud and Microsoft Systems Center family of products:
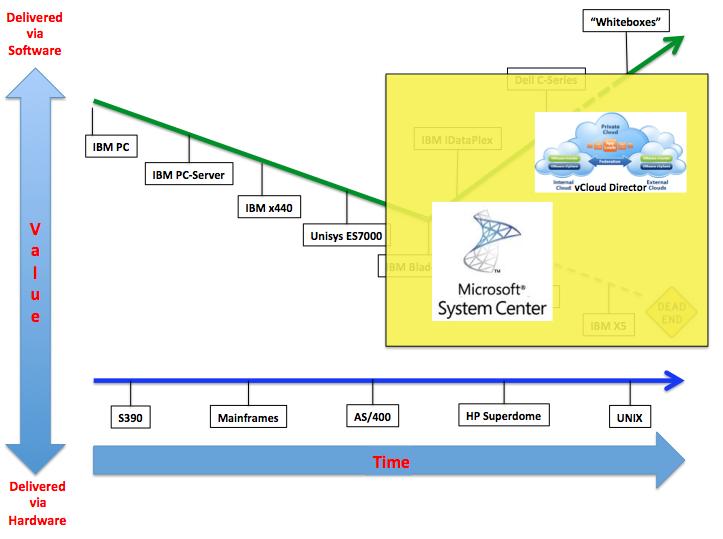
And this is the outcome for Amazon AWS:
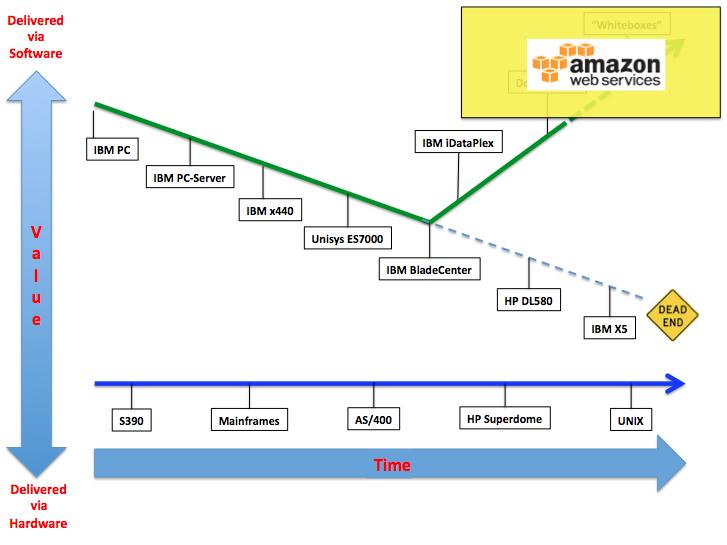
Draw your own conclusions (many of which are already in The Cloud Magic Rectangle blog post).
Massimo.