vCloud Director 1.5 Multisite Cloud Considerations
In the last few months, among other things, I have been working on the document in subject. Being able to deploy vCloud Director 1.5 across different sites is something our customers and service provider partners have been asking us a lot.
Some of these customers and partners have decided to deploy independent vCloud Director instances in different "sites", others wanted to get more clarity on how far they could stretch a single vCloud Director instance across multiple "sites". Of course both approaches present advantages and disadvantages.
We have never been very clear about the supportability boundaries other than "a single vCD instance can only been implemented in a single site". What is a single site anyway? Is it a rack? Is it a building? Is it a campus? Is it a city? Is it a region? What is it? In this paper we have tried to clarify those boundaries. We have also provided some supportability guidelines.
In the document we have described the various components that comprise a vCloud environment and we have classified them in macro areas such as provider workloads, user workload clusters and user workloads.
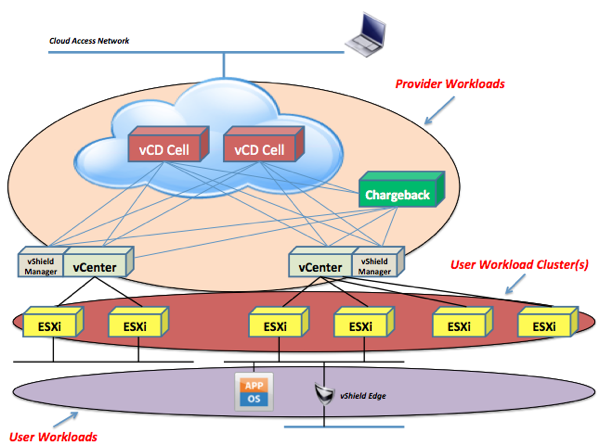
In a nutshell, throughout the document, we have tried to clarify and classify different MAN and WAN scenarios based on network connectivity characteristics (namely latency). We have determined, in our vCD parlance, what would constitute a single site deployment (over a MAN) and what would constitute a multisite deployment (over WAN). We have determined 20 ms of latency to be "our" threshold between what we can support and what we cannot support with this specific vCloud Director 1.5 release.
The document gets into a lot more details and scenarios but the two major takeaway are:
- It is not possible to stretch the provider workloads that is the software modules that comprise your VMware vCloud (e.g. vCD cells, vCD database, the NFS share, etc).
- It is possible to have Provider vDCs that are located up to 20 ms (RTT) from the provider workloads.
This picture summarizes one of the supported scenarios:
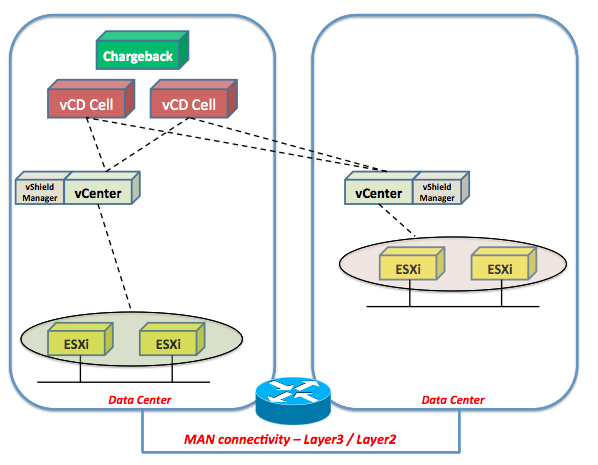
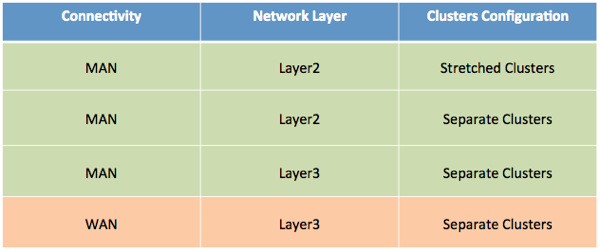
In the doc we call out and describe more precisely other supported scenarios (such as stretched clusters) and various caveats associated. The following are the scenarios we are taking into account:
It is important to understand that, when we talk about a distributed vCloud environment, we are not necessarily referring to DR of the end-user workloads. This is really about how a Service Provider can allow an end user to spin up workloads in a distributed environment. This doesn't, necessarily, mean that the SP is responsible for failing over those workloads in the other data centers. If you want to know more about how to build a resilient vCloud architecture you should read this link.
Towards the end of the document we have summarized the supportability statements associated to distributing compute resources in a vCloud setup. In the current version of the doc the summary looks like this:
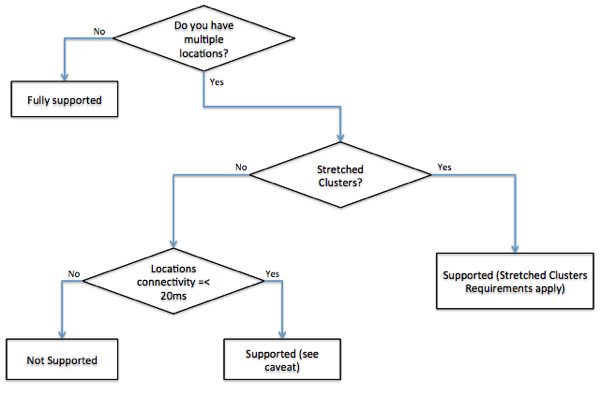
If you are evaluating a multisite vCloud Director 1.5 deployment you may want to give this document a read. Note that it isn't published externally on vmware.com but it is available through your VMware representative.
Any question, comment, feedback you may have I'd be interested to hear.
Massimo.