The ABC of Lock-In
There have been a lot of discussions lately about a topic I find extremely interesting: vendor lock-in.
Multi-hypervisor is a discipline where you can apply the high level ranting below but you can really apply it to pretty much everything in IT.
I started this blog post writing a couple of pages (as usual) and then I thought no one would care to read it (how can I blame you?). So I summarized it in a few pictures. A picture is worth a thousands words. Always.
So the story goes like... you (the customer) start with A and you build or buy an ecosystem of people, tools, knowledge, programs, scripts (yeah A has APIs) and a lot of other things you need to do to fully exploit the value of A.
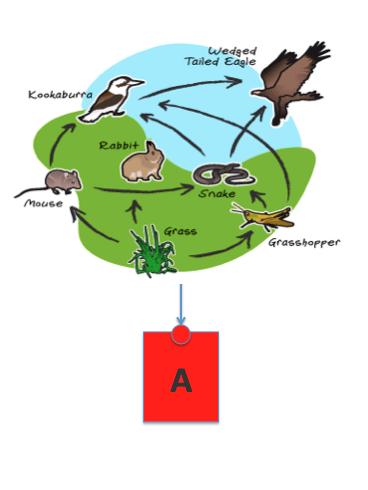
You (the customer) are happy but then comes vendor C to your door and tells you that you are locked in into A. "It isn't so easy to move away from it given all the investments you have done" he says. "Imagine if A was to apply a vTax at some point: God forbid!" C goes on. C tells you there is B now which is good and cheap and you can adopt both A and B so you are not locked in into either. "Let C manage them for you transparently" he says. And this is what happens (in theory):
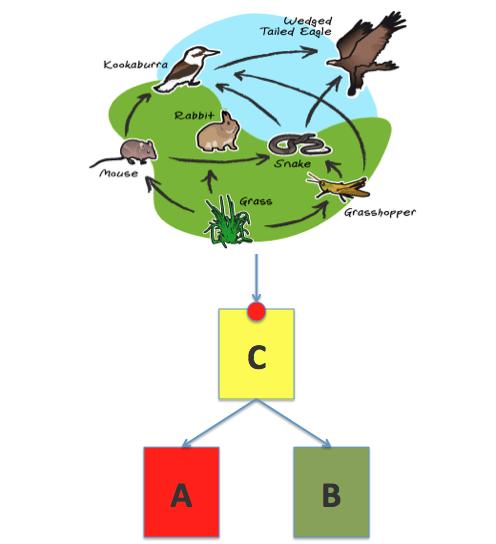
Yeah, all of a sudden you (the customer) find out that (2 years and 2M$ of professional services later) you are... locked in into C. Imagine now if C was to apply a cTax.... God forbid! You would need to move to D which is cheaper and the story goes on and on. What's your business? Bank transactions? Shoemaker? Doh I thought you wanted the infrastructure to disappear not become your core attention.
If you thought that this was the end of a sad story there is more. Actually it gets a lot worse than this. It turns out that (2 years and 2M$ of professional services later) you can actually only send "heterogenous" alerts (such as
You thought this was the end didn't you? Well not quite, there is even more:
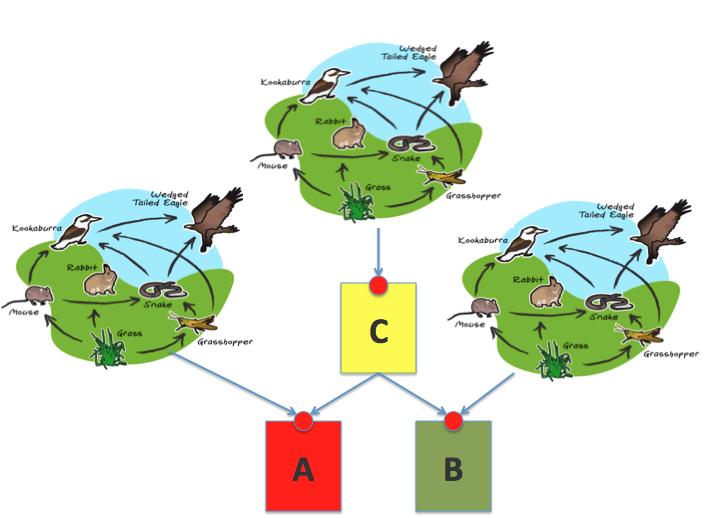
Since you can only send "the disk is full" type of alerts and provision a VM from a portal (which is neither multi-hypervisor management nor IaaS cloud by the way) you have to build another ecosystem for B similar to what you built for A, essentially doubling your past efforts (which is the reasons for which many people argue that a multi-hypervisor strategy is inefficient).
Can it get any worse than this? I can't think how.. however if it can, it will. Be sure.
Tip1: I have seen these things. First hand. You have full rights to not trust me and think I am biased now though. That's ok.
Tip2: In the interest of time (I've got work to do too) I exaggerated to make a point. Apply your common sense. Look at the forest and not at the tree in this post. I was also having some fun with some of you. You know who you are.
Discuss below if you want. I am running out of time.
Massimo.
Update: reading the comments below I am starting to realize there is a chance this post gets misread and misunderstood. I genuinelly believe there is a difference between "being able to use both A + B as loosely coupled platforms" and "using C to avoid lock-in and managing multiple platforms as one". This post was meant to say that the former is doable but can be inefficient, while the latter is just a unicorn thing. More in the discussions underneath.