Enterprise Virtualization In-a-Box
In this post I am going to talk about a specific piece of hardware technology that is intercepting a specific virtualization industry trend. This piece of technology is called BladeCenter S. Those of you that have been reading my blog know I don't usually talk about IBM specific stuff (I work for IBM) but this time I felt like the infringement of the law was worth it. Believe me or not I would have posted this anyway.
Before we get into the specific of the technology let me take a step back and briefly touch on the industry trend I was referring to. This is going to be basic stuff for most of the virtualization experts out there plus these concepts are not new and I have written/talked about those in the past. Having this said sometimes it's good to pause for a second and try to summarize what is happening in this industry. Up until the late nineties (almost) every data center looked something like this:
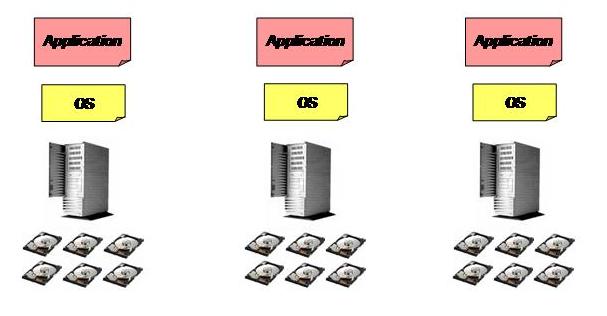
Very inflexible and vertical silos. Each silo was comprised of the following building blocks:
- A server
- A local disk subsystem (aka DAS - Direct Attached Storage)
- An operating system
- An application
Do you have 100 application services? Deploy 100 of these independent silos! Have you ever heard virtualization (true or appointed) experts talking about how bad life was those days? Look at the picture... and you can imagine how life was. I can tell you: it was very bad (compared to what we have today obviously, at that time it was... OK).
At the beginning of the 21st century we have started to see the very first form of "visible" virtualization of an x86 IT infrastructure. I am using the world "visible" because someone might argue that the concept of virtualization was already included in the OS under the form of memory virtualization (physical memory Vs virtual memory etc ; I am not interested in these academic discussions and I am not interested in determining where virtualization first appeared in the x86 ecosystem (we can stay here for days without getting to any useful outcome). I want to focus more on tangible things that end-users/human beings (not IT geeks) understand and can appreciate. Having defined the context, the first form of "visible" virtualization of an x86 IT infrastructure was the storage and particularly the consolidation of all Direct Attached Storage into a single pool of storage resources called SAN (Storage Area Network). And since my mantra is that a picture is worth 1000 words, here it is how a common x86 IT infrastructure looked like at the beginning of this century:
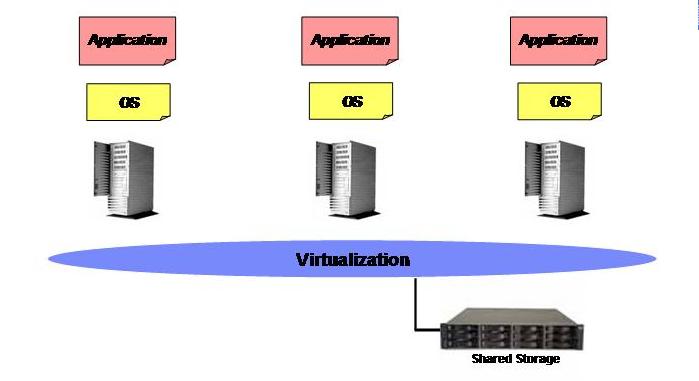
Note: If you ask 100 storage specialists nowadays what storage virtualization is you might very well get 100 responses (perhaps more?) ranging from "Raid 0 is the basic form of storage virtualization" all the way to "a storage grid (whatever that is) is the only form of storage virtualization". I am using here the word virtualization in the context of storage to describe the high level practice of decoupling the disk subsystem from the servers and locate it into a common resource pool.
Back to the basic this is what customers have been doing for the last 10 years or so: getting rid of this locally attached / inefficient / inflexible disk subsystem and move (almost) all the disk spindles into a central repository that is the so called Storage Server (the physical data repository attached to the SAN). The very first advantage that this has brought to customers is a more efficient and flexible way to use the storage space; someone might refer to this as Storage Consolidation. On the other hand shared consolidated storage brought in (as a bonus I would say) a brand new architecture that allowed customers to do things that were not simply possible before. One example for all is High Availability clusters: in the good old days of DAS (and the inflexible silos described at the beginning) your application data would most likely be hold physically on the same server that was running the application. Should that server fail you couldn't access any longer your data (unless you restore them from a backup); with SAN shared storage this changed as you can now "attach on the fly" the same set of data to another server and restart the application from there while being consistent in terms of data persistency. Microsoft Cluster Server, anyone?
Well time goes by and right now storage virtualization is no longer the hot topic (I guess everyone recognizes it as more of a prerequisite to run an efficient IT). The buzz word today is server virtualization and, if you think about it, it's the natural progression of what we have seen happening in the past: it's about taking the silo apart and move additional stuff below the virtualization bar. We have done that with storage, who's next? Did I ever say a picture is worth 1000 worth?
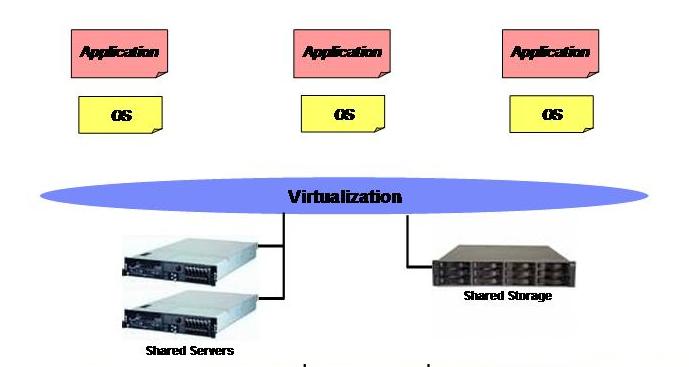
This is where we are today basically. VMware pioneered this concept some 10 years ago and there is now a string of companies that have realized the benefits of this and are working hard to deliver products to implement this idea. I started working on server virtualization some 8 years ago and at that time it was all about server consolidation (i.e. how many servers do you have? 100? we can bring them down to 5 etc . The more I was working on it the more I understood that we were only scratching the surface of the potentials. Today server consolidation is still a huge advantage for those customers virtualizing but it's clearly only one of the many advantage line items. As it was for storage virtualization we started with the consolidation concept to find out that there were many other hidden and indirect advantages as a bonus of doing that. One example for all is that, as you virtualize your Windows or Linux systems, it becomes far easier to create a Disaster/Recovery plan for your x86 IT infrastructure.
Last but not least the server virtualization trend is intimately associated to the storage virtualization (i.e. SAN) trend for two key reasons:
- the standard server virtualization best practices require shared storage to exploit all the benefits
- server virtualization is allowing customers to get rid (completely) of local attached storage. While data has been historically moved to a shared repository (SAN) the standard "2 x Raid1 drives pair" remained a (negative) legacy of the x86 deployments. The latest trends (that are embedded hypervisors on flash disks and/or PXE boot techniques for the hypervisors) will help getting rid completely of all the local server spindles for good!
So why am I so excited about the BladeCenter S you might wonder? Well the BladeCenter S maps exactly the industry trend I have described above. Instead of going out for shopping and cabling together all these elements (servers, SANs, etc) BladeCenter S is a single package that contains them all: servers, storage and network! Enterprise Virtualization In-a-box! Or a data-center-in-a-box if you will!

What you see here is basically the physical view/package of the de-facto-standard hardware architecture to support virtual environments. The key point I am trying to outline here is that the disks you see integrated into the chassis are really connected to a true fully redundant internal SAN comprised of 2 x SAS redundant RAIDed switches. It essentially maps the standard servers to storage architecture blue-prints we have been using in the last few years to implement shared storage virtualized deployments. The following picture, for example, is an extract from the standard VMware SAN configuration guide and it illustrates this standard blue-print (which is mapped into the BladeCenter S internal architecture):
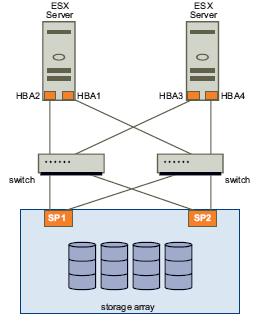
Notice that the only slight difference is that the SAS switches integrated into the BladeCenter S deliver both switch as well as SP functionalities.
It might perhaps help sharing with you some more documentation I have been working on and that we presented at the local VMware Virtualization Forum that took place in Milan a few days ago. The following picture describes the internal architecture of the BladeCenter S in further details:
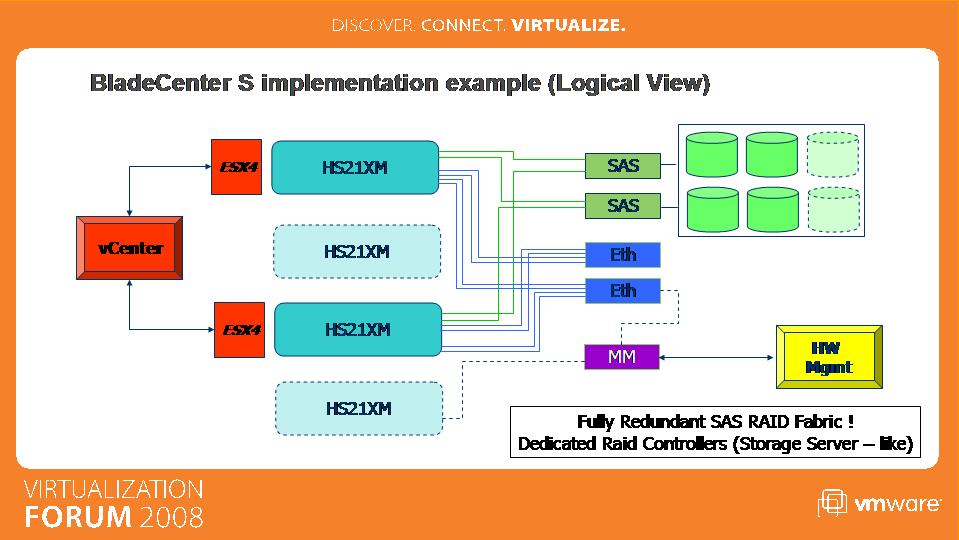
Notice how the servers-storage connections are similar in concept to those in the standard VMware blueprint (but not limited to VMware deployments though) attached above. Each blade is equipped with a dual-port SAS HBA which in turn connects to 2 x SAS RAIDed switches which control the disks. For those of you familiar with the IBM storage products family this is very similar to what happens when you connect ESX servers to an external DS3200 SAS Storage Server configured with dual controllers. Since in the last few months I have been talking to customers and partners that were pretty confused about what this really is and how it compares to other implementations available in the industry I did want to outline what other blade vendors are doing to underline the differences:
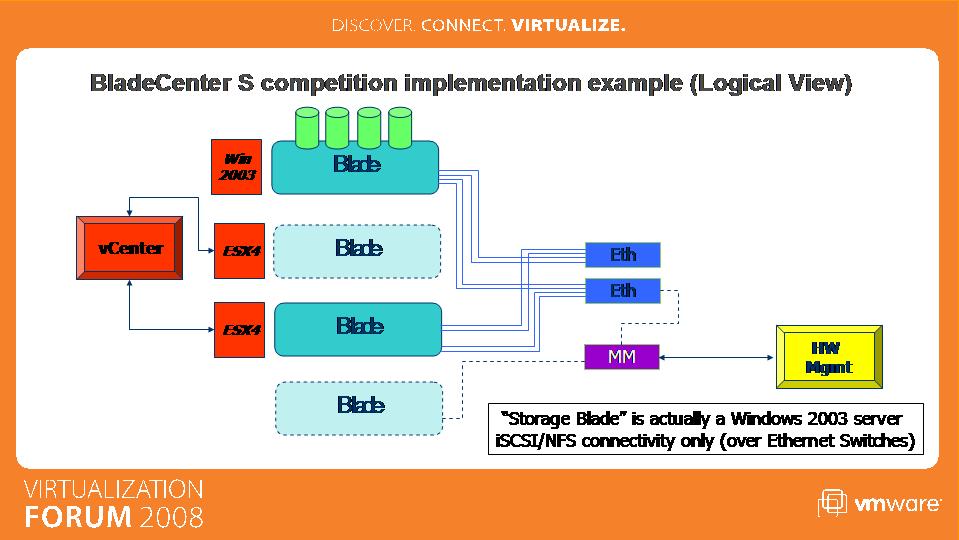
While from a physical standpoint it might look pretty similar (i.e. "a chassis with a bunch of blades and a bunch of disks") if you dig into the internals it's of course completely different. The other option outlined in the picture above involves dedicating a single blade (hence a Single Point Of Failure) with Windows Server 2003 Storage Server and a bunch of disks attached to it. The Windows instance running on the Storage Blade controls the disks and exposes them onto the internal Ethernet network via NFS/iSCSI protocols. This is how other blades in the chassis can "share" those disks. There are, obviously, fundamental differences between having a multi-purpose Windows blade sharing disks over the network compared to using a standard and fully redundant SAN approach comprised of a dedicated couple of purpose designed SAS RAID switches that control the disks and map those disks to compute nodes (i.e. the blades dedicated to the virtual infrastructure). The following picture reminds the physical layout of the BladeCenter S with the integrated SAN.

On the left hand side you can see the front of the chassis where the disks (we had 4 of them in our demo on-site) and the blades (2 x HS21XM in our setup) are installed. On the right hand side the rear view of the BC S chassis shows the 2 x Ethernet switches (that can support up to 4 Ethernet connections from each of the blades) and 2 x SAS RAIDed switches (that control the disks on the front of the chassis and are connected to the blades by means of the SAS daughter cards).
Another interesting point I wanted to outline via this setup is that the BladeCenter S is really meant to be a self-contained data center. This doesn't only include the standard User Workloads (i.e. the guests that are going to support the customer own environment such as Active Directory, Databases, Web Servers, Application Servers etc) but it also includes all the additional services that are required to configure, monitor and maintain the data center (in a box). Examples of these System Services include the vCenter service (red rectangle in the figure above) which can be installed on top of the virtual infrastructure as well as what I refer to as the HW Management service which is the suite of software products that are used to manage the hardware and its configuration (the yellow rectangle in the figure above - it might include things like IBM Systems Director, IBM Storage Configuration Manager etc). The logical view shows these two services (vCenter and HW Management) as external entities that map respectively the ESX hosts comprising the virtual infrastructure and the Management Module (MM for short) that is the heart of the BladeCenter chassis. There is no reason though for which these services need to be installed physically outside of the BladeCenter "domain". A forward-looking take of these services is to consider them a sort of _System Partition_s that run side by side with the end-user workloads. These System Services, as of today, need to be installed manually but ideally in the future they could potentially be distributed as Virtual Appliances (yes Virtual Appliances is my obsession, sorry) for a more streamlined and fast deployment.
In the next few screenshot I'd like to give you a high-level feeling of what happens when you connect to the HW Management service to configure the hardware components (the shared storage in this case). For this setup I have only installed the IBM Storage Configuration Manager in that HW Management System Partition.
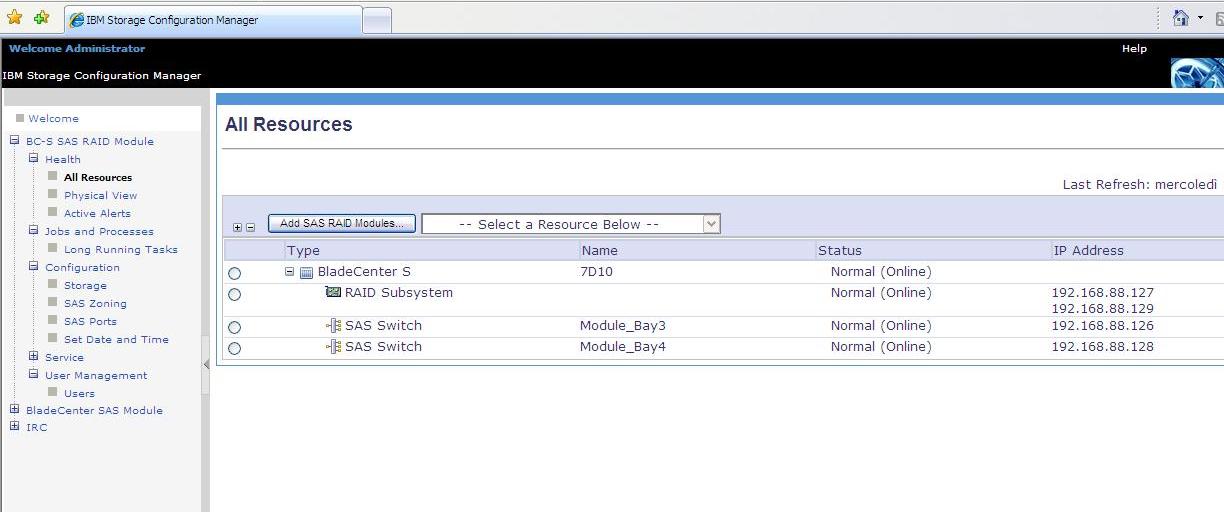
First you connect, via web, to the SCM service. One of the main screen summarizes the actual internal hardware storage configuration which is a RAID subsystem comprised of 2 x SAS switches:
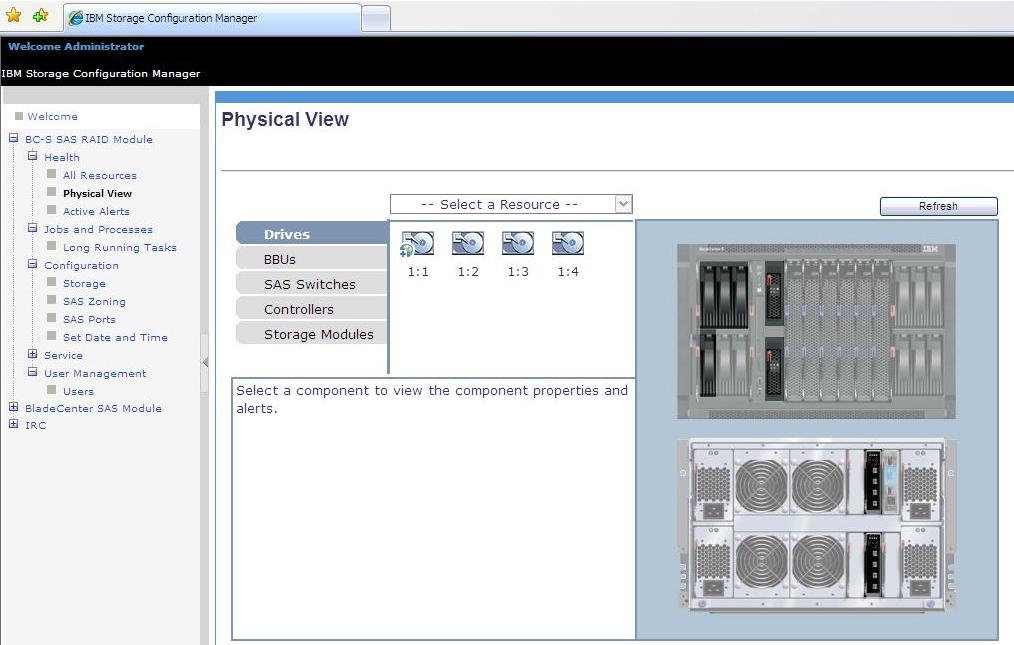
Next is the physical view of the chassis. As you can see we have 4 x physical disks plugged into the front of the chassis and 2 x physical SAS switches in the back of the chassis (the two additional devices you notice in the front are the SAS controller caches). A maximum of 12 physical disks can be installed:
The following view details the characteristics of the physical hard disks:
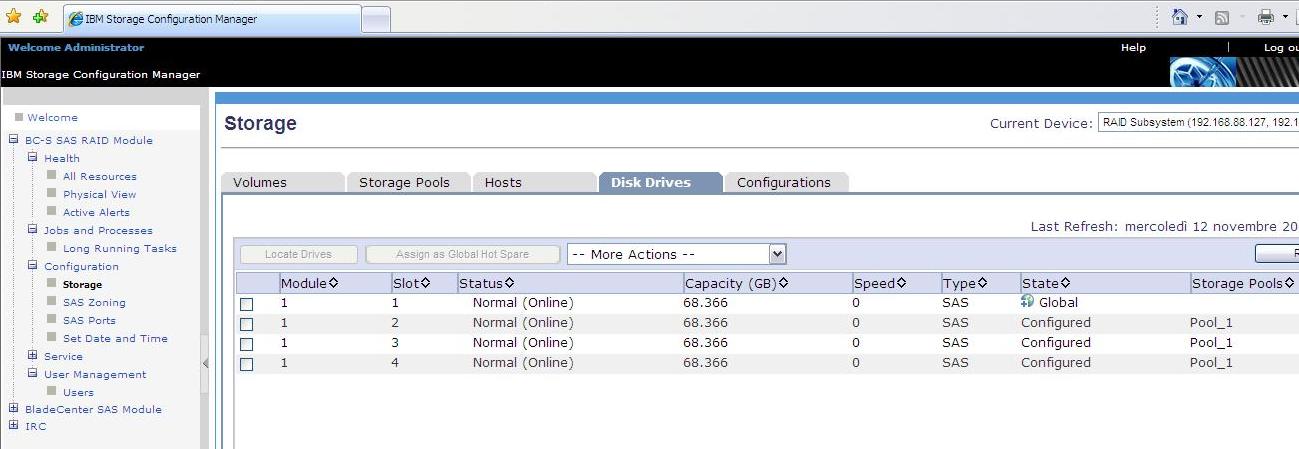
Next we create a Storage Pool (aka Array) comprised of these 4 physical drives. This is a very basic configuration where we designate one of the disk as a global hot spare and three of the disks as a Raid 5 Storage Pool. Total available capacity is 2 disks (1 is used for parity in a RAID 5 array). Notice that the space available is basically 0 because I have already created LUNs out of this array (see next):
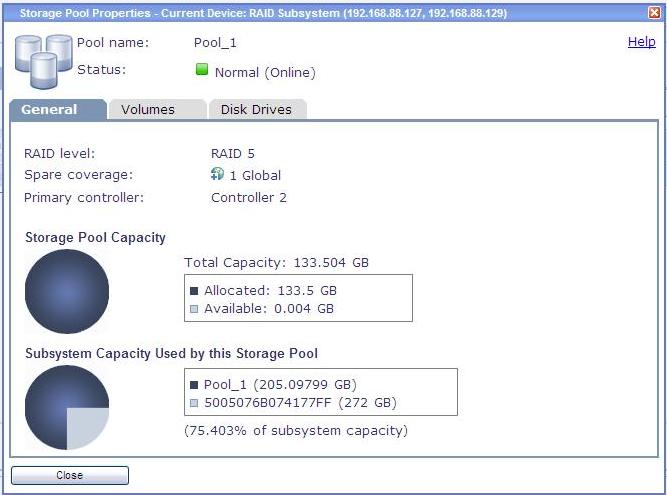
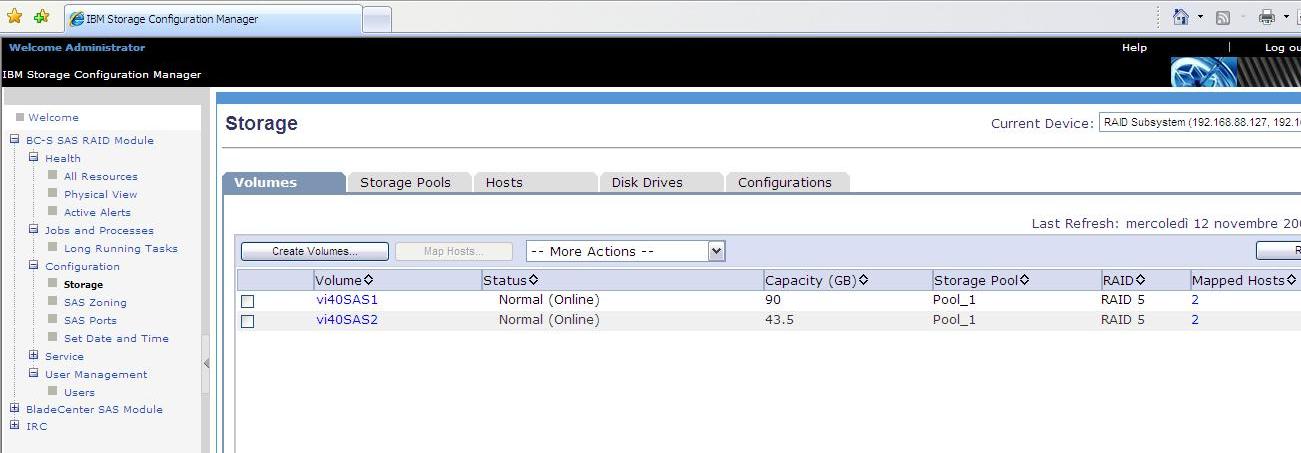
These are the two Logical Units (aka LUNs) that I have created using the Storage Pool described above. One is 90GB and the other one is 43GB in capacity:
The following view lists the discovered SAS daughter cards (hence the corresponding blades) on the SAS fabric. Notice that each blade has two ports for redundancy and each port has its own SAS WWN. This is not any different from a standard FC configuration for those of you used to Storage Area Networks:
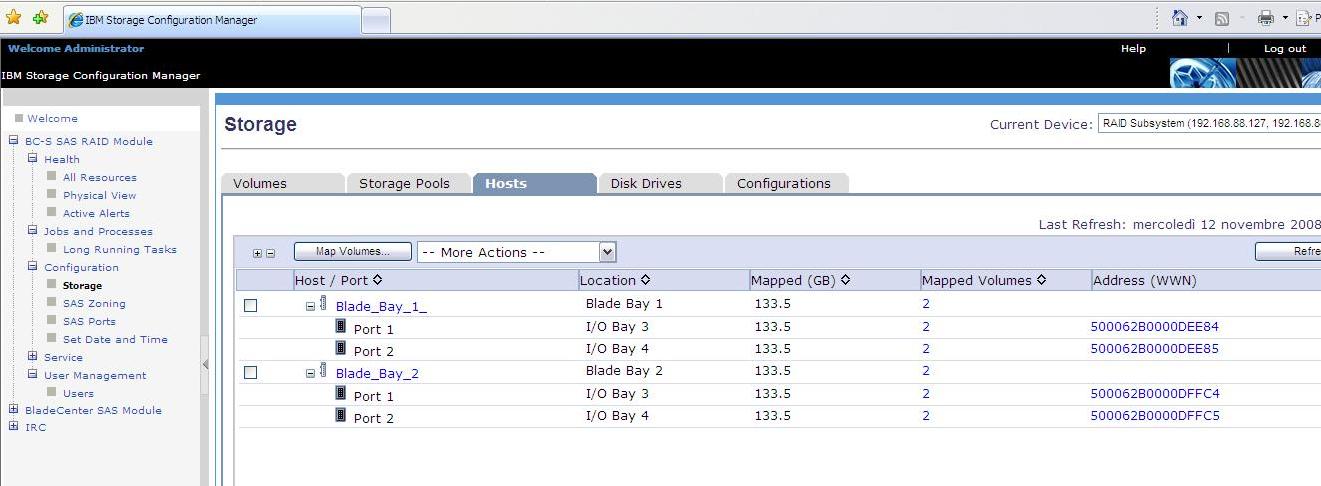
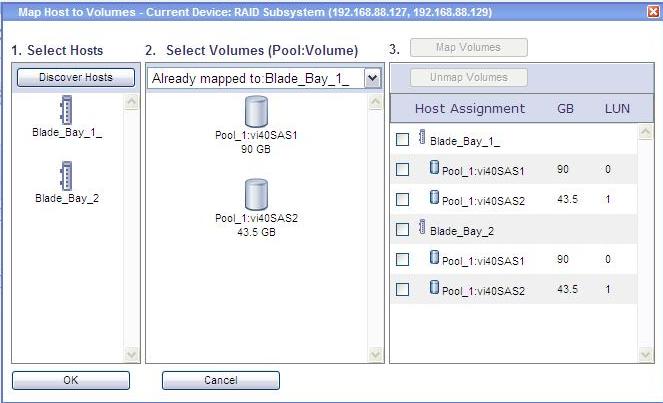
This is how I have mapped Servers to LUNs. On the left hand side I have listed both blades whereas on the right hand side I have listed both LUNs I have created. Doing so I allowed both blades to share both LUNs. There is no particular reason for which I have created 2 LUNs. I could have created 1 or 3 or 4 if I wanted/needed to and I would have been able to share them with both blades:
So far we have been working against the HW Management to configure the hardware (this example is limited to configuring the shared storage). Now we can switch gear and we can connect to the other System Partition to manage the virtual infrastructure software. In this case we will connect to the vCenter service to configure our VMware infrastructure. Notice that, although I have been using a beta version of the next VMware virtual infrastructure product, everything you will see here can be done with the latest VI3 version available today.
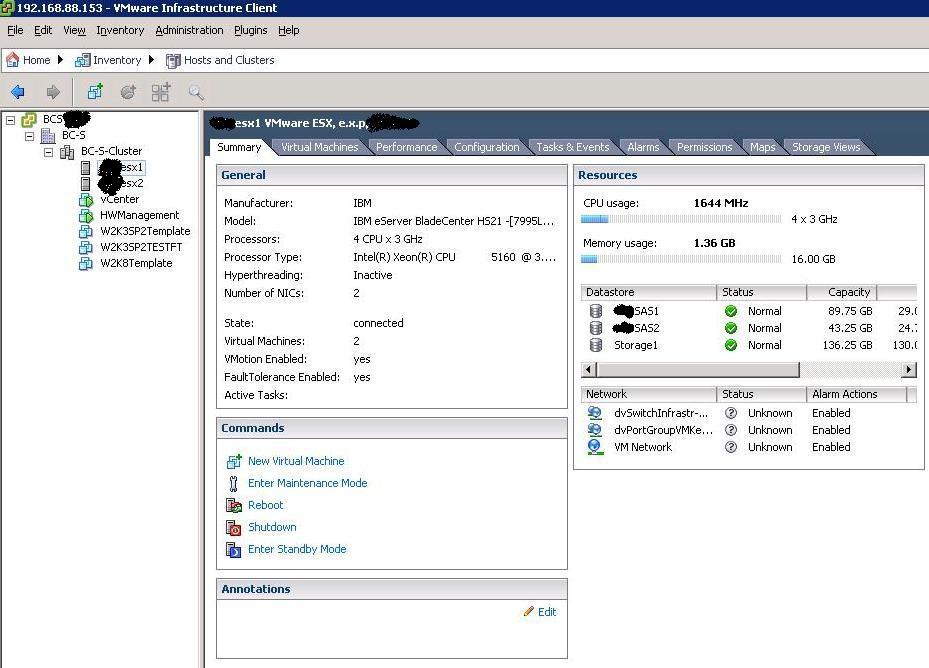
The following screenshot outlines the overall configuration of our data-center-in-a-box. As you can see there are 2 blades equipped with ESX and they belong to a cluster. On these blades we have created the two management partitions we have been discussing (vCenter and HW Management). There are also some Guests templates I have created. One important thing to notice from this screenshot is that the first blade can access both shared SAS LUNs (for the records it can also access its own dedicated/local Storage1 VMFS volume):
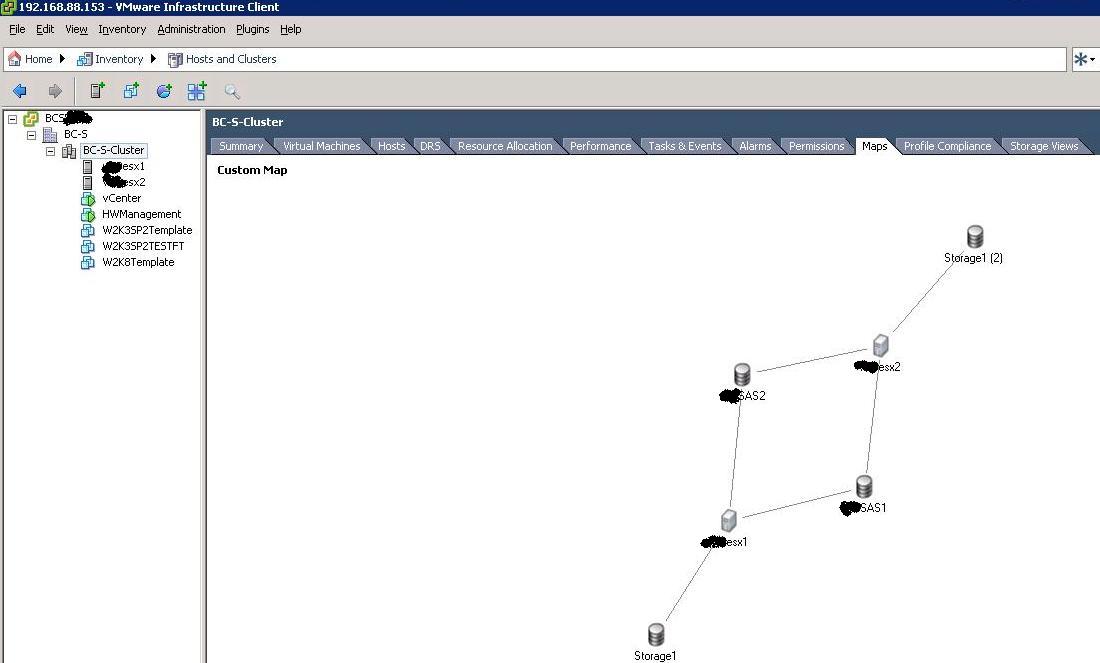
The next picture confirms that both blades can access the shared LUNs created. This allows all VMware advanced features such as VMotion, DRS, HA etc:
Here we will attempt a VMotion of the HW Management partition running on esx1 onto the other host in the cluster:
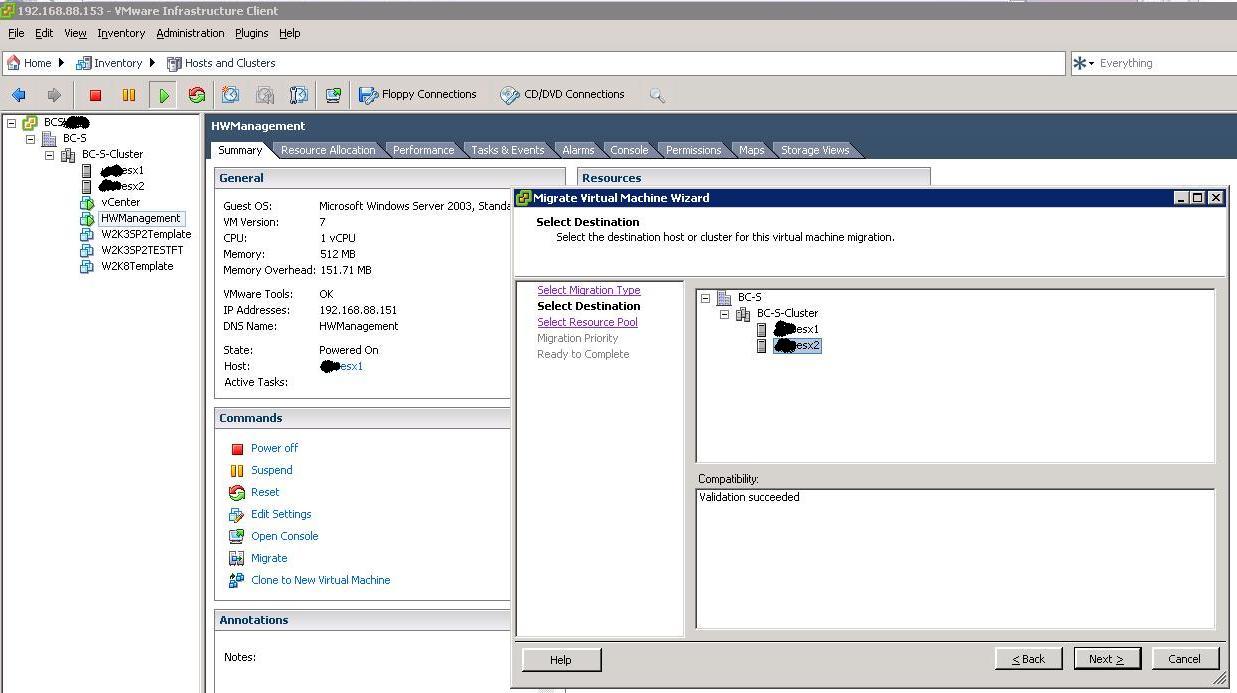
The Guest is being moved from one host onto the other. Notice the status bar at the bottom:
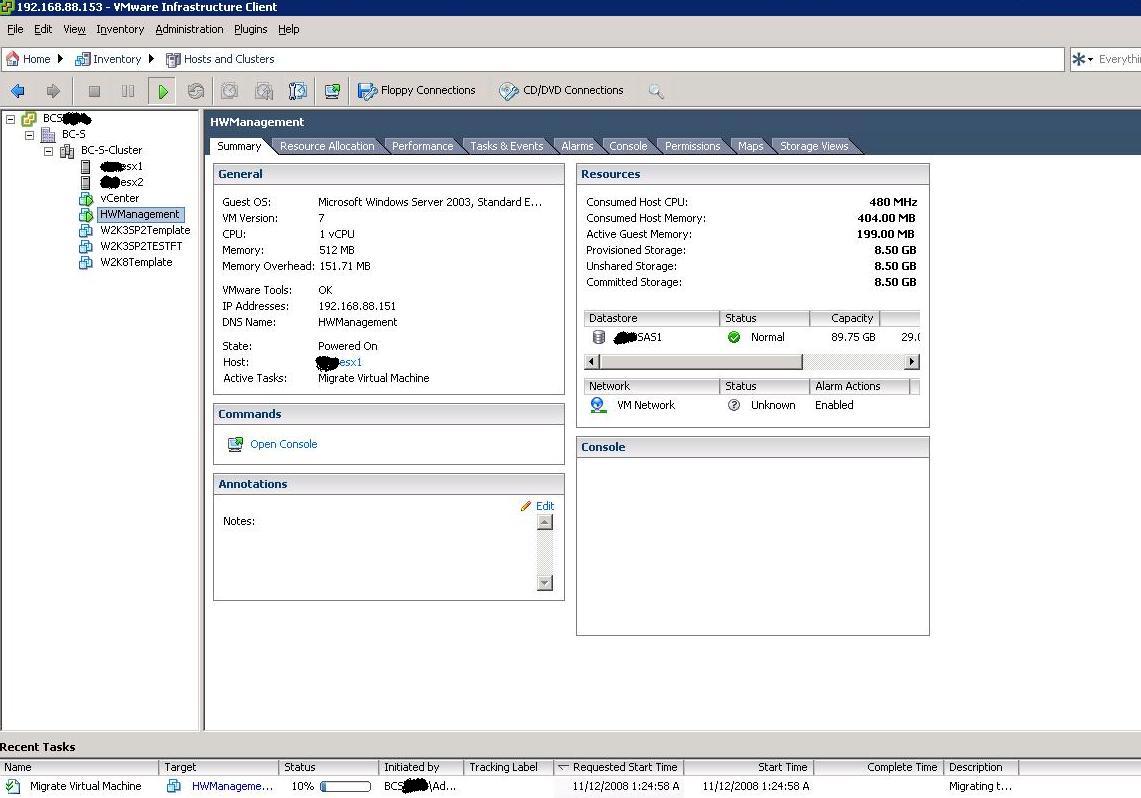
And here the Guest has moved and it's now running on esx2 as you can see from the Summary pane (and the status bar at the bottom):
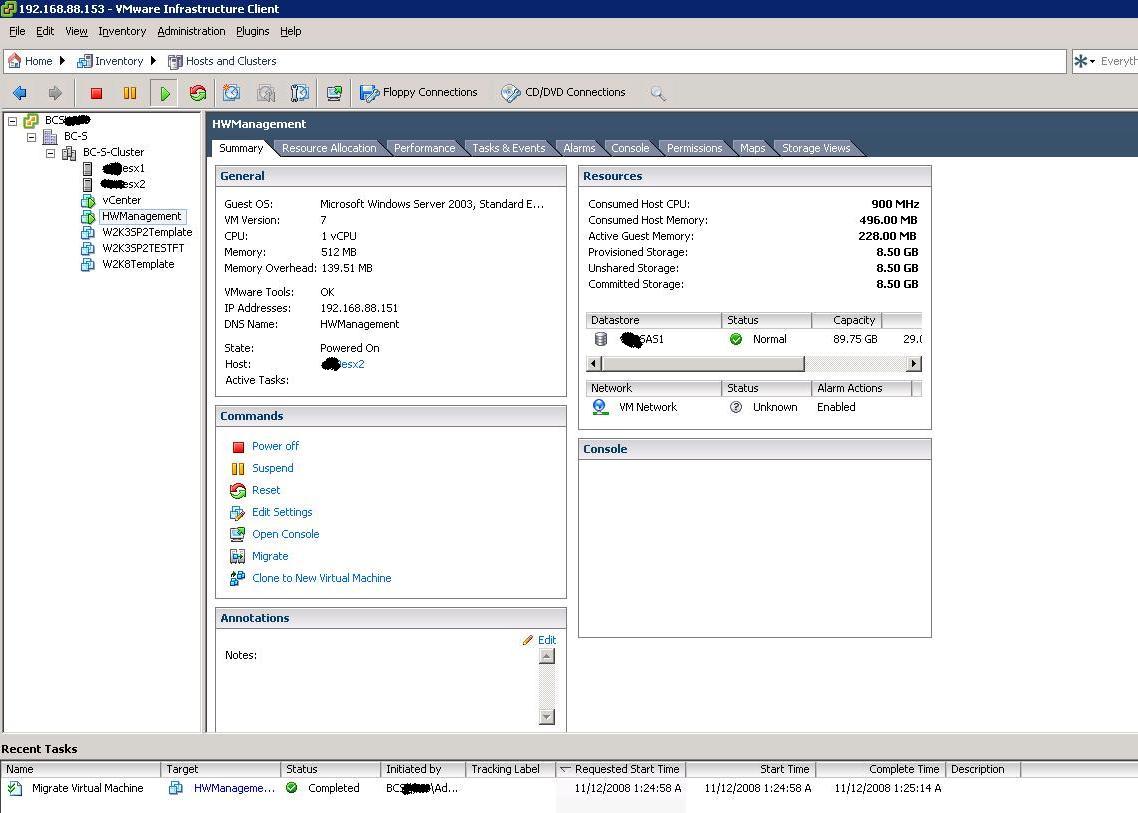
I truly believe that the BladeCenter S is a piece of technology that is sometimes under valuated. There is an enormous potential in it that many people haven't fully exploited. It's really what I would describe as a no-compromise Enterprise "pocket" data center. Not so much "pocket" after all because if you think that an HS21XM blade could support, on average, some 15/20 VMs (depending on the workload), we are talking about a 7U Enterprise solution that could support around 100 VMs. Far more than what an average SMB shop might require.
Massimo.