A brief architecture overview of VMware ESX, XEN and MS Viridian
It is my feeling that there has been a bit of confusion lately around how hypervisors are being positioned by the various vendors. I am specifically referring to the three major technologies that seem to be the most relevant strategically going forward:
- VMware ESX
- Microsoft Viridian
- Xen
VMware ESX is the VMware flagship hypervisor product: it's the basis for the Virtual Infrastructure version 3 framework.
MS Viridian is the next generation hypervisor that Microsoft is going to use in the Longhorn time frame and that is currently being developed. It's basically the successor of Microsoft Virtual Server.
Xen is an opensource hypervisor that is being integrated by a number of players which include RedHat, Suse, XenSource and Virtual Iron.
All these vendors (VMware, Microsoft, RedHat, Suse, XenSource, Virtual Iron) are pitching their own virtualization solutions as being the optimal implementation. I don't want to discuss this in the very details because it would require a pervasive understanding of the very low level technologies required to design these products (which I don't have) but I would rather try to go through a very high level analysis to either demystify or (try to) clarify some of the points. I have in fact had a chance to participate to some events hosted by these various vendors and it appears to me they are using some high-level facts at their own convenience to try to demonstrate their design is better than others'. Which is fair and obvious.
There are three major areas of confusion for us "human beings" trying to determine which approach and which solution makes more sense. These areas are:
- The architectural implementation of the hypervisor: this includes discussions like "my hypervisor is thinner than yours" etc etc.
- The hardware assists (Intel-VT, AMD-V) dilemma: "my hypervisor uses cpu hardware extensions to do what you do in software so it's faster than yours" or viceversa.
- The paravirtualization dilemma: "my hypervisor can support this modified guest hence it's (or it will be) faster than yours" etc etc.
Let's try to dig into all three.
My hypervisor is thinner than yours!
As I said I have been to some vendor presentations of these technologies and all of them tried to outline how their architecture was better than the others. There are many details one would need to discuss but I think that the majority of the people (virtualization customers, potential virtualization customers and virtualization IT professionals) are interested in major details only. There are in fact two main different reference architectures one could depict out of the 3 major platforms (i.e. VMware ESX, MS Viridian and Xen) as you could see from the diagrams below (the charts are taken as-is from public documents).
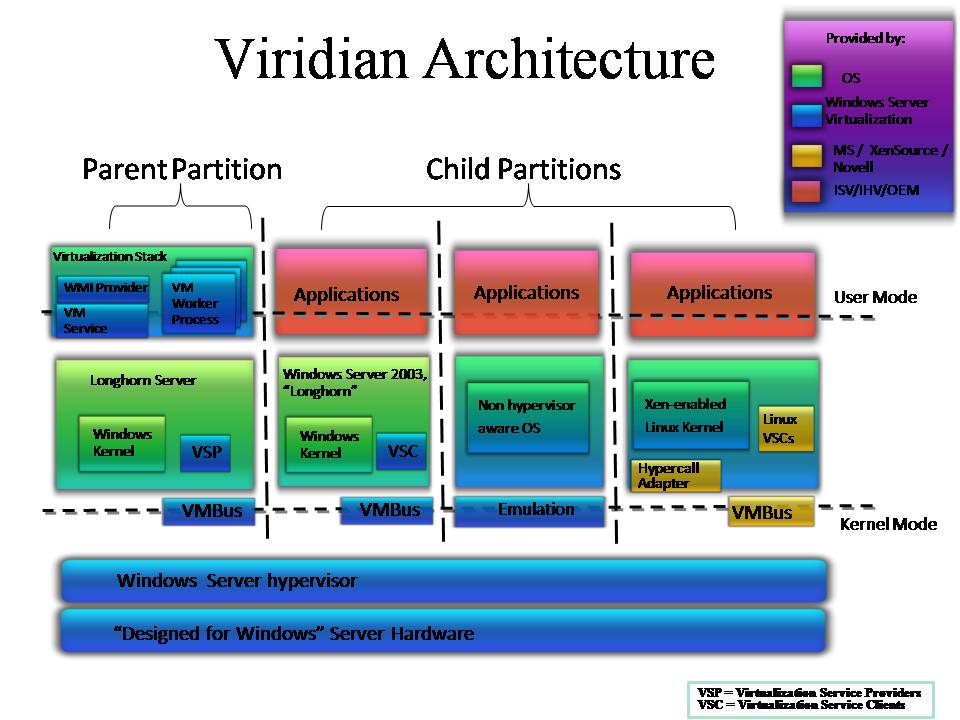
The first diagram outlines the internal architecture of VMware ESX; the second diagram outlines the internal architecture of the MS Windows Server Virtualization (aka Viridian) hypervisor while the third diagram describes the internals of the Xen architecture. Notice that while this diagram has been taken as-is from a XenSource presentation the internals of Xen do not change whether it's being used by the XenSource package, by the Virtual Iron package, by the RedHat or Suse packages (well the details might vary but the overall internal design doesn't).
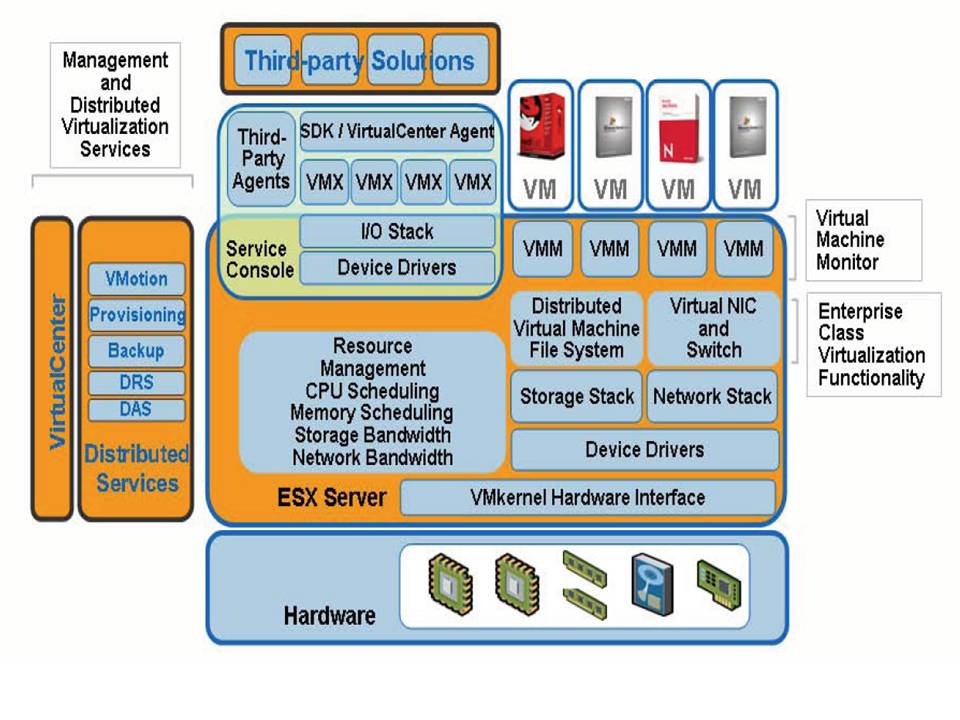

As you could see from these pictures VMware ESX implements what it is referred to as the "VMKernel" which is a bundle of hypervisor code along with the device driver modules used to support a given set of hardware. The size of the VMkernel is known to be in the range of some 200.000 lines of code or a few MBytes. On top of that there are a so called VMware Console OS that is in fact a sort of system virtual machine that is used to accomplish most administrative tasks such as providing a shell to access the VMkernel, the http and VirtualCenter services to administer the box. The Console OS is not typically used to support virtual machines workloads as everything is handled by the VMkernel.
On the other hand Viridian and Xen implement a different philosophy where the so called "Parent Partition" and "Dom0" play a different role than the Console OS. The hypervisor implementation in Viridian and Xen is much smaller than that in the ESX implementation and in fact it is in the range of some few thousands lines of code (vs the 200.000 of the VMKernel) or some KBytes (vs the MBytes of the VMKernel). However the Viridian/Xen implementation pretty heavily involves the usage of the Parent Partition / Dom0 as far as device drivers are concerned. In fact they are using these two entities to "proxy" I/O calls from the virtual machines to the physical world. On top of this proxy function of course the Parent Partition and Dom0 also provide higher level management functions similarly to the VMware Console OS. So in my opinion claiming that the Viridian / Xen hypervisor is "thinner" than the VMKernel is partially true since VMware decided (for their own convenience) to put stuff into the VMKernel that on the other solutions did not just evaporated... they are merely called differently and are included in different "locations".
Let me be clear, I am not saying that the ESX architecture is better than the Viridian/Xen architecture or viceversa. I am saying that if you look at the overall picture they have very different internal mechanisms to achieve similar things. Unfortunately Viridian is not yet available so any performance claim needs to be discussed later but as far as we can see there are no "huge" differences between ESX Vs Xen micro-benchmarks at the moment (at least not big enough to say "this architecture works best, period!") so I think it's fair enough to suggest not to bother about these implementation details because different vendors have taken different routes (for their convenience, heritage etc etc) but are likely to provide similar results in terms of performance.
My hypervisor uses cpu hardware extensions to do what you do in software so it's faster than yours (or viceversa)
Another dilemma that is being discussed a lot lately has to do with these new hardware instructions that Intel and AMD have introduced over the last couple of years with their CPU's. Intel calls them Intel-VT while AMD calls them AMD-V (or Pacifica). Essentially what they do is providing a hook for those that develop virtualization software to make the processor appear more "virtualization-aware". Historically the x86 processors has never supported any form of virtualization in the sense that it was a common assumption that a given server (or PC) would have run one and only one Operating System supporting various applications (most likely one per OS given the limited cooperation of applications in the x86 stack). Various techniques have been developed over the past few years to overcome this limitation and VMware pioneered a philosophy called "binary translation" where the hypervisor would trap privileged instructions issued by the guest and re-work them so they play nice in a virtual environment. This allows running an unmodified guest OS within a virtual machine and it is indeed a powerful idea. Xen comes from a different perspective and what has been historically used to overcome this problem was something called "paravirtualization". It essentially means that instead of having the hypervisor "adjust" privileged calls issued by a standard guest OS... the guest gets modified (i.e. paravirtualized) in order to play "natively" nice in a virtual environment. This of course requires a change in the guest OS kernel and it is not by chance that historically paravirtualized Linux guests were the only virtual environments supported by the Xen hypervisor (the Xen community did not, for obvious reasons, have access to the Windows source code so they could not "patch" it). We will return on this paravirtualization concept later.
Intel-VT and AMD-V started to change all this. Now a hypervisor can leverage these new hardware instructions rather than implementing a "complex trap and emulate logic" that is very challenging to develop and tune for optimal performance. So what happened in the last months is that the Xen hypervisor has been modified to take advantage of these new instructions so that you could run unmodified guests on top of Xen (Windows and standard Linux distributions).
So we have now a situation where VMware continues to implement this "binary translation" to support standard operating systems while Xen has provided support for standard operating systems by means of these "hardware assists". We are in the middle of this marketing battle where VMware claims that their software "binary translation" is faster than the hardware assists implementation (i.e. "we have tuned binary translation for more than 10 years while hw assists are an immature technology that has just appeared and might perhaps be convenient to use by those that do not have the knowledge to develop binary translation") while Xen claims the opposite (i.e. "we leverage high-performance native hardware instructions while others are still using their legacy and slower software mechanisms"). The battle is tough and it creates confusion among the community.
The reality is that, based on the latest benchmarks published by the vendors (and biased accordingly of course) there is no much different between the two implementations. They are both right in my opinion. It is true that, ideally, you would run something faster in a native hardware implementation but at the same time it is also true that a 10 years fine tuned "software trick" can be even faster than a version 1 hardware implementation. We are at an inflection point where perhaps VMware still has a little bit of performance advantage and that is the reason for which they are sticking for the moment on their own software implementation but there is no doubt that going forward, as these hardware instructions mature, that is the path to follow. On the other hand it would have made absolutely no sense for Xen (or Viridian) to even think about developing a complex "trap and emulate" trick just for this very limited time frame. We did not touch on Viridian (it's not yet available after all) but their implementation and philosophy is very similar (or will be very similar) to that described hereafter for Xen.
Notice that to complicate things further VMware currently requires Intel-VT to support 64-bit guests. This has nothing to do with the general performance discussion above but it is rather due to the fact that Intel removed some "memory protection logic" using standard x86 instructions and in order to achieve the same result for 64-bit guests VMware requires the usage of some Intel-VT instructions. Again this has nothing to do with implementing hypervisor functions in the software or leveraging the hw ... as a matter of fact you do not need AMD-V to run 64-bit guests on ESX (it is a very Intel peculiar thing).
This is yet another example of different vendors coming from different backgrounds and trying to solve the same problem in different manners. As per the "my hypervisor is thinner than yours" quite frankly I don't see at the moment (June 2007) a technology that prevails over the other by large. As I said perhaps VMware has a little advantage (otherwise it would have been easy for them to use the hardware assists as well) but based on the numbers I see it's not enormous. They will all eventually migrate to leverage these hardware instructions especially with the upcoming releases that introduce more features such as memory virtualization (i.e. AMD Nested Page Tables and Intel Extended Page Tables) but for the moment you need to deal with all their marketing messages.
My hypervisor can support this modified guest hence it's faster than yours
This is the most tricky and complex of all three. That is the case because it can get complex from a technical perspective and also because it is still pretty much up in the air. I have already touched on the concept of paravirtualization above. A paravirtualized guest is basically an OS running in a virtual machine that has been optimized (i.e. the kernel has been optimized) so that it knows it is running in virtual environment.
Let's step back for a second here. I downplayed a little bit this concept in my analysis above (i.e. you cannot run Windows etc etc) but in reality this landscape has been changed by two things:
- Since RedHat and Suse integrated Xen in their distribution they have also shipped fully supported paravirtualized kernels (previously the patching was provided by the open source community basically under the form of a kernel hack and obviously this was not very well perceived by many customers that required fully supported stacks)
- MS is going to "enlight" (enlightenment is the MS word for paravirtualization) their own operating systems moving forward to be optimized to run on Viridian.
Back to the point there are really two set of thoughts currently in the industry (I warned you it's still up in the air). The first thought is that these new hardware assists hardware (especially in future implementations) has diminished the need of paravirtualizing the guest. These hw implementations will be so efficient and optimized that there will be no need to optimize the guest OS as well and even a standard OS (i.e. non paravirtualized) will perform close to native speed. The other thought is that, other than the efficiency and optimization provided by these low level hardware instructions there is room to improve performance by paravirtualizing the Guest OS in areas where Intel-VT and AMD-V would have little effect. This second thought is backed by the fact that given points #1 and #2 above there would be no more supportability issues as Suse, RedHat and Microsoft are going to provide their own fully supported paravirtualized versions of their own OS kernels.
In my personal opinion this mix of hardware assists virtualization along with OS paravirtualization (or enlightenments) is what we will see most likely in the future. Which brings in the problem of paravirtualization/enlightenments standards. If the actual need of paravirtualization is still up in the air (i.e. will hardware assists support be enough to provide near native performance?) what is going to happen with the standards is even more speculative. However we can try to speculate.
As far as Linux is concerned VMware has submitted to the open source community a tentative paravirtualization standard called VMI. Apparently the Linux open source community has accepted the idea but decided to adopt a slightly different standard to be included into the main kernel called paravirt-ops. The difference between paravirt-ops and VMI is not in the idea of providing a common/standard paravirtualized interface but it is mostly around the implementation details. The idea behind this newly accepted standard is that a single standard Linux kernel could run within a Xen vm, a VMware vm or on a physical server using different (and optimized!) paths in the kernel code depending on the "context" it is running in. It is important to stress that the idea is that there will not be a "hardware kernel" and a "standard virtual kernel" but a single kernel that could run independently on a specific physical hardware as well as any virtualization stack that adhere to the standards.
On Windows the matter is quite different for obvious reasons. MS has already announced that they will paravirtualize (i.e. enlight) their Windows kernel so that it will run optimized on the Viridian hypervisor. It is still to be seen whether this "enlightenment interface" will be compatible with the paravirtualization standards being discussed in the Linux community (along with VMware).
One of the possible options is that Microsoft will work through technology partnerships with Novell and XenSource (both use the opensource Xen hypervisor) to optimize the linux kernel to run on Viridian as you could depict from the MS chart at the very beginning of this post. Other operating systems might only be able to work through legacy and not optimized emulations (this would include older MS operating systems that won't or couldn't be enlightened). Whether this enlightenment API work will converge with the paravirt-ops it is still to be seen.
Even more interesting and up in the air is whether MS will try to avoid Hypervisor ISV's/communities to be able to implement these interfaces in their own products (i.e. they want to avoid, for example, VMware to be able to implement Viridian-like enlightenments support so that they won't be able to run a Viridian-optimized Windows enlightened kernel).
Given the technology partnership it might be easier for Novell and XenSource to implement these interfaces in Xen but one would expect MS to be very concerned about letting other hypervisors run an enlightened Windows kernel as fast as they would run it on Viridian. Only time will tell I guess.
Should this happen, this is clearly not in the interest of the customer since the best thing would be to define a single standard (or a set of multiple standards if they really need to) so that everybody would have a chance to innovate and improve without any impediment restricted by proprietary interfaces.
But fair-play is not, apparently, a characteristic of this business lately. However, as I said at the beginning of this third section, this is still pretty much up in the air and these have been speculations on possible future situations that might be proven wrong.
Massimo.